
David Silver Reinforcement Learning
David Silver reinforcement learning broken down in plain English, plus a simple flashcard + spaced repetition workflow so the MDPs and algorithms actually.
Want AI flashcards + spaced repetition on iPhone? FlashRecall is free to start (signup required; paid plans optional).
What Is David Silver Reinforcement Learning? (And Why Everyone Talks About It)
Alright, let's talk about what people mean when they say "david silver reinforcement learning" — it’s basically the famous lecture series and book material by David Silver that explains how computers learn by trial and error. Reinforcement learning (RL) is a type of machine learning where an agent takes actions, gets rewards or penalties, and slowly figures out the best way to behave. This is the stuff behind things like AlphaGo, game-playing AIs, and smarter decision systems. The reason everyone loves David Silver’s material is because he breaks down really heavy math and concepts into a logical, step‑by‑step path that a motivated beginner can actually follow. And honestly, it’s the perfect kind of content to turn into flashcards and learn with spaced repetition using something like Flashrecall:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Quick Overview: What Reinforcement Learning Actually Is
So, super simple:
- You have an agent (the learner/AI)
- You have an environment (the world it interacts with)
- At each step the agent:
- Sees a state (what’s going on)
- Chooses an action
- Gets a reward (good/bad)
- Moves to a new state
Over time, the agent tries to maximize total reward. That’s reinforcement learning in one sentence.
David Silver’s RL material walks through:
- What an MDP (Markov Decision Process) is
- How to evaluate policies (how good a strategy is)
- How to improve policies
- How to learn from experience when you don’t know the environment
This is why his stuff is kind of the “default” learning path for RL.
Where David Silver Reinforcement Learning Comes From
You’ll see his name in a few places:
- The famous UCL RL course (video lectures on YouTube)
- Lecture slides and notes that are shared online
- Concepts that are heavily used in DeepMind research (he’s a lead researcher there)
His lectures cover:
1. Introduction to RL
2. Markov Decision Processes
3. Planning by Dynamic Programming
4. Model-Free Prediction
5. Model-Free Control
6. Value Function Approximation
7. Policy Gradient Methods
8. Integrating Learning and Planning (Dyna)
9. Exploration and Exploitation
10. Case Studies (like AlphaGo)
Each of these is packed with definitions, formulas, algorithms, and little tricks that are very easy to forget if you just watch the video once.
This is where having a good flashcard workflow (like with Flashrecall) honestly makes the difference between “I kind of watched it” and “I actually remember it.”
Why David Silver’s RL Course Is So Popular
People love it because:
- It’s mathematically solid but still approachable
- It lines up well with the Sutton & Barto RL book
- It builds concepts in a logical order
- There are concrete algorithms you can implement (like Q-learning, SARSA, Policy Gradient)
The downside?
It’s dense. You might understand it while watching, but a week later you’re like:
- “Wait… what’s the Bellman equation again?”
- “What’s the difference between on‑policy and off‑policy?”
- “Why does Q-learning converge but SARSA behaves differently under exploration?”
This is exactly the kind of content where active recall + spaced repetition is your best friend.
How To Actually Study David Silver’s Reinforcement Learning Material
Here’s a simple way to not drown in it:
1. Watch or Read in Small Chunks
Flashrecall automatically keeps track and reminds you of the cards you don't remember well so you remember faster. Like this :

Don’t binge 3 lectures in a row. Take one main topic at a time:
- MDPs
- Dynamic Programming
- Model-Free Methods
- Policy Gradient
- Etc.
After each chunk, pause and make notes or, better, turn them straight into flashcards.
With Flashrecall you can literally:
- Paste text from slides or PDFs
- Screenshot equations or diagrams
- Turn them into cards in seconds
App link again so you don’t scroll back up:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
2. Turn Key RL Concepts Into Flashcards
Here’s how I’d break it down.
- Q: What is a Markov Decision Process (MDP)?
A: A tuple (S, A, P, R, γ) with states, actions, transition probabilities, rewards, and discount factor.
- Q: What is the Bellman equation for Vπ(s)?
A: Vπ(s) = Σₐ π(a|s) Σₛ′ P(s′|s,a) [R(s,a,s′) + γ Vπ(s′)]
- Q: Difference between value-based and policy-based methods?
A: Value-based learns value functions and derives policy; policy-based directly parameterizes and optimizes the policy.
- Q: Core idea of Q-learning?
A: Off-policy TD control that updates Q(s,a) toward r + γ maxₐ′ Q(s′, a′).
- Q: SARSA update rule?
A: Q(s,a) ← Q(s,a) + α [r + γ Q(s′,a′) − Q(s,a)] (on-policy).
In Flashrecall, you can:
- Make these manually if you like control
- Or just drop your notes and let it generate cards for you automatically from text, PDFs, or screenshots
3. Use Spaced Repetition So You Don’t Forget The Math
Reinforcement learning is full of little details that fade fast:
- Discount factor γ meaning
- Different flavors of TD learning
- Exploration strategies like ε-greedy, UCB, etc.
Flashrecall has built-in spaced repetition with auto reminders, so:
- You don’t have to remember when to review
- Hard cards show up more often
- Easy cards get spaced out over longer intervals
So while you’re slowly progressing through the David Silver lectures, Flashrecall is quietly scheduling your reviews in the background.
Why Flashcards Work So Well For David Silver’s RL Content
RL learning is basically:
- Tons of definitions
- Lots of equations
- Subtle differences between algorithms
Perfect flashcard territory.
With Flashrecall, you get:
- Active recall built in – you see the question, try to answer from memory, then reveal the answer
- Offline support – you can drill Bellman equations on the train, plane, or in a boring meeting
- Fast, modern interface – so you’re not wrestling with clunky UI when you just want to study
- Works on iPhone and iPad – good if you like a bigger screen for equations
And if you get stuck on a concept, you can even chat with the flashcard to get more explanation and context, instead of hunting through the lecture again.
Turning David Silver’s Slides, PDFs, And Videos Into Flashcards
Here’s a practical workflow you can use:
Step 1: Grab The Material
- Download the lecture slides (PDFs)
- Maybe keep the Sutton & Barto RL book nearby
- Have the YouTube playlist of the lectures open
Step 2: Create Cards While You Learn
In Flashrecall, you can:
- Import PDFs and have cards generated from key sections
- Take screenshots of equations or diagrams and instantly turn them into cards
- Paste in definitions, theorems, or algorithm steps as text
Examples:
- Screenshot a slide showing the Bellman optimality equation → make a card: “What equation is this and what does it represent?”
- Copy a pseudo-code block for Q-learning → front: “Q-learning algorithm steps?” back: the pseudo-code in short bullet form
Step 3: Mix Theory + Intuition Cards
Don’t just memorize formulas; also add intuitive questions:
- Q: Intuition behind discount factor γ?
- Q: Why is exploration important in RL?
- Q: When would you prefer policy gradient over Q-learning?
This makes you actually understand David Silver’s reinforcement learning content, not just parrot it.
How Flashrecall Compares To Other Flashcard Apps For RL
You’ll see people using stuff like Anki for RL, but here’s where Flashrecall is nicer for this kind of technical content:
- Way faster card creation from PDFs, screenshots, text, YouTube links, and typed prompts
- Built-in chat with your flashcards – super handy when a formula or algorithm step isn’t clicking
- Clean, modern UI that doesn’t feel like using a tool from 2005
- Free to start, so you can try it on one lecture’s worth of content and see if it sticks
For something as dense as David Silver reinforcement learning, speed and ease of making cards actually matters. If it’s annoying, you just won’t keep up with it.
Again, here’s the link so you can grab it on iPhone or iPad:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Example Flashcard Deck Structure For David Silver’s RL Course
If you want a concrete structure, try this:
Deck 1: RL Basics & MDPs
- Definitions: agent, environment, reward, return, policy, value function
- MDP components & Markov property
- Bellman expectation equations
Deck 2: Dynamic Programming
- Policy evaluation
- Policy improvement
- Policy iteration vs value iteration
Deck 3: Model-Free Prediction & Control
- Monte Carlo methods
- TD(0)
- SARSA vs Q-learning
Deck 4: Function Approximation
- Why we need approximation
- Linear value function approximation
- Issues like divergence
Deck 5: Policy Gradient
- Objective function J(θ)
- REINFORCE algorithm
- Advantages of policy gradient vs value-based
Deck 6: Exploration & Advanced Topics
- Exploration strategies
- Dyna architecture
- Case study concepts (like key ideas from AlphaGo)
Review these with spaced repetition and you’ll be in a way better place than just “I watched the playlist once.”
Final Thoughts: How To Actually Remember David Silver Reinforcement Learning
If you just watch the lectures, you’ll feel smart for an hour and then forget 70% of it.
If you:
1. Watch/read in small chunks
2. Turn the most important ideas into flashcards
3. Use spaced repetition to keep them fresh
…you’ll actually own this material.
That’s exactly what Flashrecall is built for: fast card creation, active recall, automatic spaced repetition, and study reminders so you don’t fall off.
If you’re serious about learning David Silver reinforcement learning properly instead of half-remembering it, set up a deck and start while you go through the first lecture:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Frequently Asked Questions
What's the fastest way to create flashcards?
Manually typing cards works but takes time. Many students now use AI generators that turn notes into flashcards instantly. Flashrecall does this automatically from text, images, or PDFs.
Is there a free flashcard app?
Yes. Flashrecall is free and lets you create flashcards from images, text, prompts, audio, PDFs, and YouTube videos.
How do I start spaced repetition?
You can manually schedule your reviews, but most people use apps that automate this. Flashrecall uses built-in spaced repetition so you review cards at the perfect time.
Related Articles
FlashRecall app preview
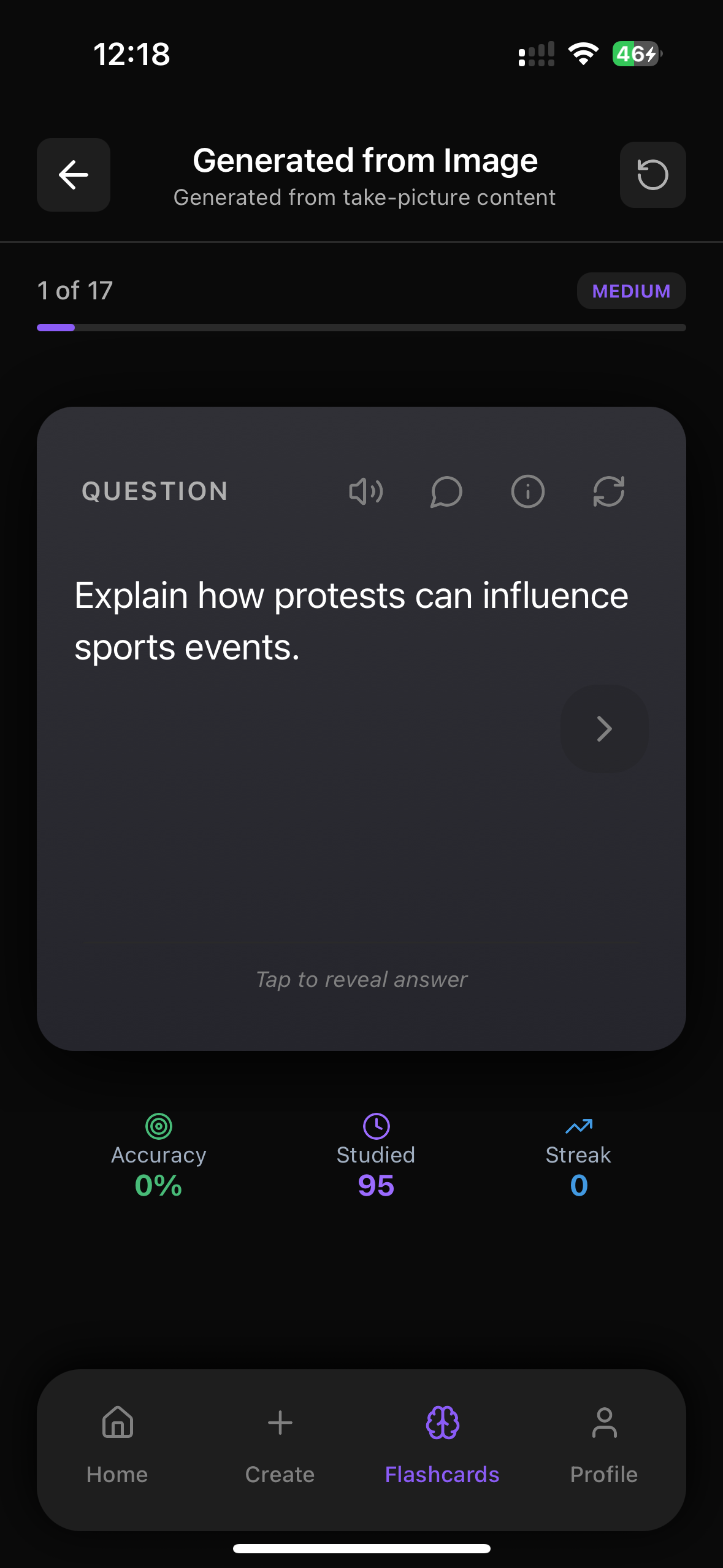
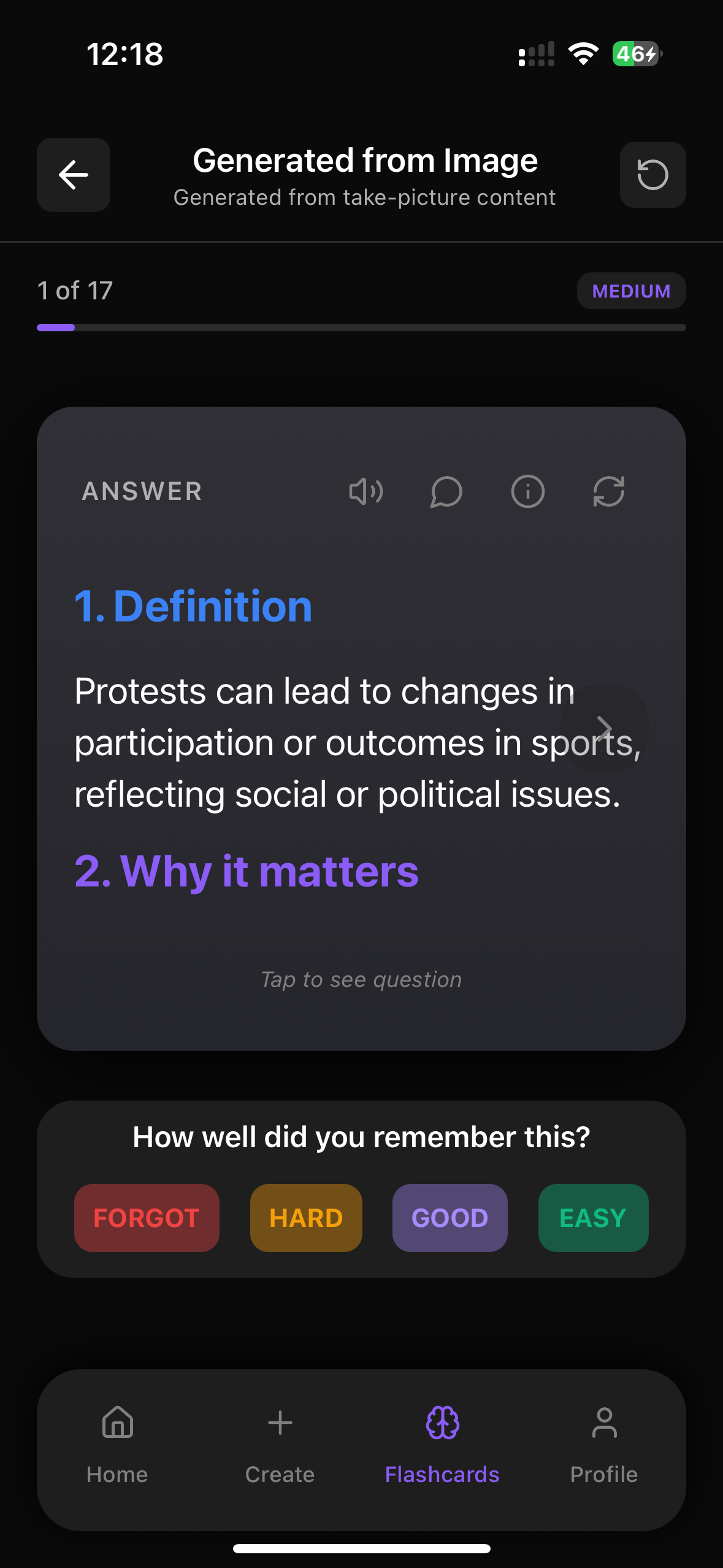
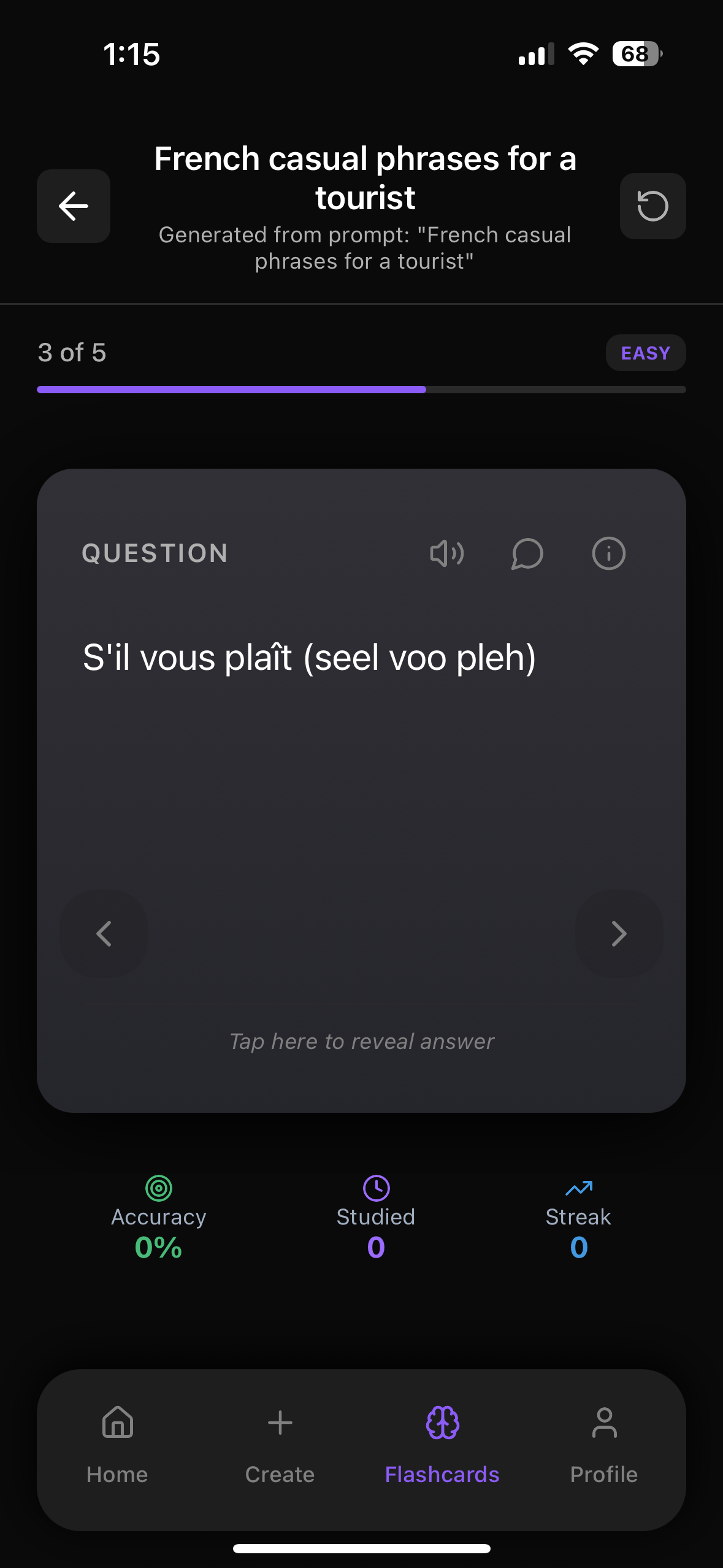
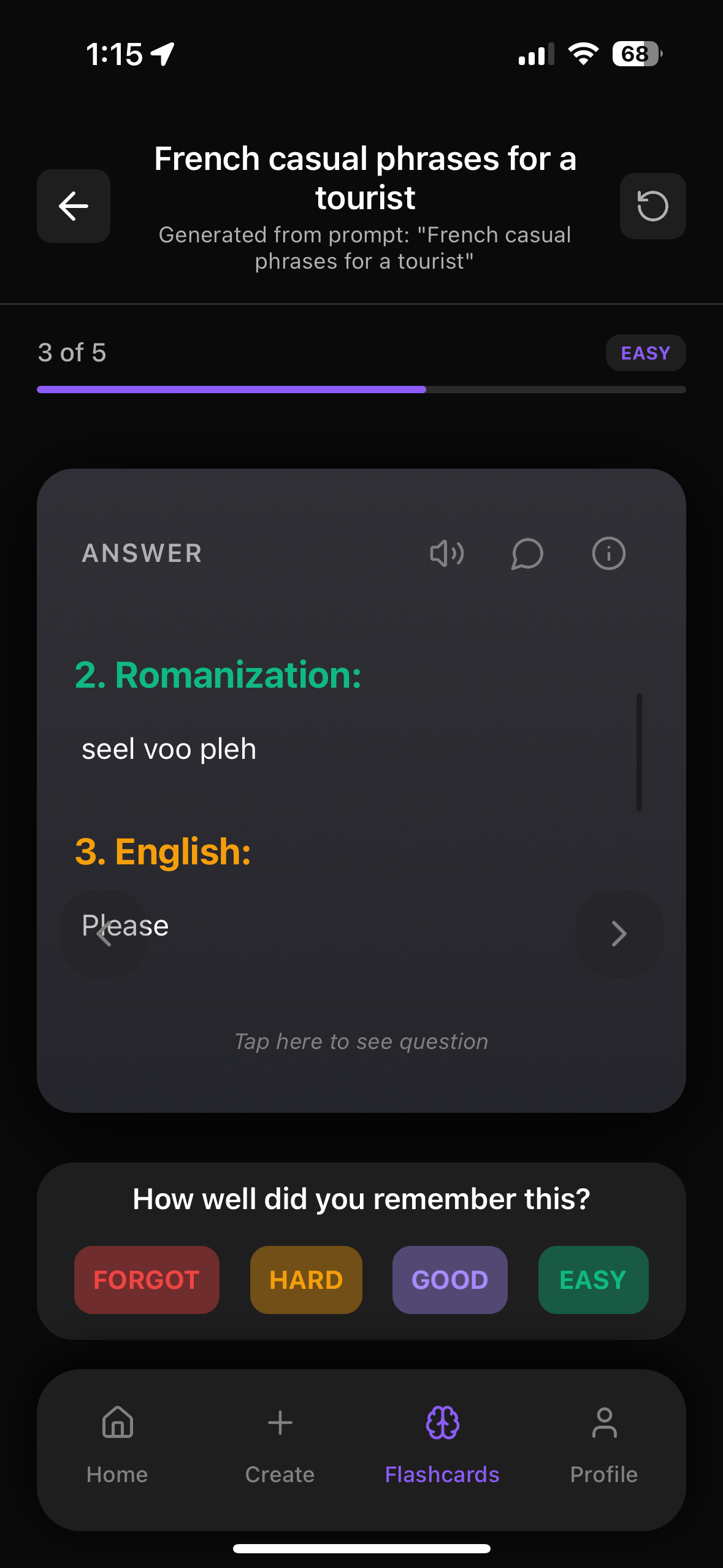
Practice This With Web Flashcards
Try our web flashcards right now to test yourself on what you just read. You can click to flip cards, move between questions, and see how much you really remember.
Try Flashcards in Your BrowserInside the FlashRecall app you can also create your own decks from images, PDFs, YouTube, audio, and text, then use spaced repetition to save your progress and study like top students.
Research References
The information in this article is based on peer-reviewed research and established studies in cognitive psychology and learning science.
Cepeda, N. J., Pashler, H., Vul, E., Wixted, J. T., & Rohrer, D. (2006). Distributed practice in verbal recall tasks: A review and quantitative synthesis. Psychological Bulletin, 132(3), 354-380
Meta-analysis showing spaced repetition significantly improves long-term retention compared to massed practice
Carpenter, S. K., Cepeda, N. J., Rohrer, D., Kang, S. H., & Pashler, H. (2012). Using spacing to enhance diverse forms of learning: Review of recent research and implications for instruction. Educational Psychology Review, 24(3), 369-378
Review showing spacing effects work across different types of learning materials and contexts
Kang, S. H. (2016). Spaced repetition promotes efficient and effective learning: Policy implications for instruction. Policy Insights from the Behavioral and Brain Sciences, 3(1), 12-19
Policy review advocating for spaced repetition in educational settings based on extensive research evidence
Karpicke, J. D., & Roediger, H. L. (2008). The critical importance of retrieval for learning. Science, 319(5865), 966-968
Research demonstrating that active recall (retrieval practice) is more effective than re-reading for long-term learning
Roediger, H. L., & Butler, A. C. (2011). The critical role of retrieval practice in long-term retention. Trends in Cognitive Sciences, 15(1), 20-27
Review of research showing retrieval practice (active recall) as one of the most effective learning strategies
Dunlosky, J., Rawson, K. A., Marsh, E. J., Nathan, M. J., & Willingham, D. T. (2013). Improving students' learning with effective learning techniques: Promising directions from cognitive and educational psychology. Psychological Science in the Public Interest, 14(1), 4-58
Comprehensive review ranking learning techniques, with practice testing and distributed practice rated as highly effective

FlashRecall Team
FlashRecall Development Team
The FlashRecall Team is a group of working professionals and developers who are passionate about making effective study methods more accessible to students. We believe that evidence-based learning tec...
Credentials & Qualifications
- •Software Development
- •Product Development
- •User Experience Design
Areas of Expertise
Try FlashRecall on iPhone
Free tier after signup. AI flashcards from your notes, spaced repetition, and optional paid upgrade when you need more.
Download on App Store