
Deep Reinforcement Learning: The Ultimate Beginner’s Guide To How It
deep reinforcement learning broken down like you’re cramming before an exam—agents, rewards, policies, value functions, plus an easy way to memorize it all.
Want AI flashcards + spaced repetition on iPhone? FlashRecall is free to start (signup required; paid plans optional).
What Is Deep Reinforcement Learning? (Explained Like You’re 5 Minutes From an Exam)
Alright, let’s talk about deep reinforcement learning: it’s basically when an AI learns to make decisions by trial and error, using deep neural networks to figure out which actions lead to good outcomes over time. Instead of just memorizing data, it acts in an environment, gets rewards or penalties, and slowly learns what works best. Think of it like training a dog with treats, but the “dog” is a neural network and the “treats” are math-y reward signals. This is how we get AIs that can play games like Go, control robots, or optimize complex systems. And if you’re trying to actually study and remember deep reinforcement learning concepts, an app like Flashrecall (https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085) makes it way easier to lock in all the definitions, equations, and intuition.
Quick Big-Picture View
Before diving into details, here’s the high-level idea:
- Reinforcement learning (RL) = learning by doing, using rewards.
- Deep learning = using deep neural networks to handle complex inputs (like images, text, large state spaces).
- Deep reinforcement learning (DRL) = RL + deep learning → an agent uses a neural network to choose actions in an environment to maximize long-term reward.
Classic example: an AI playing Atari games just from the pixels on the screen and the game score as reward. It presses buttons randomly at first, then slowly learns strategies that give higher scores.
The Core Pieces of Deep Reinforcement Learning
Let’s break it down into simple parts.
1. The Agent and the Environment
You have two main characters:
- Agent: the learner/decision-maker (the AI).
- Environment: the world it interacts with (game, robot world, stock market simulator, etc.).
On each step:
1. The agent sees a state (what’s happening right now).
2. It picks an action.
3. The environment responds with:
- A new state
- A reward (positive, negative, or zero)
The goal: pick actions that maximize total future reward.
2. Rewards and Return
The agent doesn’t just care about the next reward; it cares about long-term rewards.
- Reward: immediate feedback (e.g., +1 for scoring, -1 for crashing).
- Return: the sum of future rewards (often discounted over time).
That’s why DRL can learn strategies like “take a small hit now to get a big payoff later.”
3. Policies and Value Functions
Two super important concepts:
- Policy: how the agent chooses actions.
- Deterministic: given a state, always pick the same action.
- Stochastic: pick actions with certain probabilities.
- Value function: how good a state (or state-action pair) is in terms of expected future reward.
- State-value: “If I’m in this state, how good is it overall?”
- Action-value (Q-value): “If I take this action in this state, how good is that?”
Deep reinforcement learning uses neural networks to approximate these policies and value functions.
So Where Does “Deep” Come In?
The “deep” part is just deep neural networks.
Instead of simple tables or linear models, DRL uses networks that can:
- Take in huge or complex inputs:
- Raw images (e.g., game screens)
- Sensor data
- Long state vectors
- Learn complex patterns and strategies.
For example, in Atari games, the input is just pixels. A convolutional neural network processes those images and outputs Q-values for each possible action.
Popular Deep Reinforcement Learning Algorithms (In Plain English)
You’ll see these names everywhere, so here’s the simple rundown.
1. Deep Q-Networks (DQN)
- Learns a Q-function: how good each action is in each state.
- Uses a neural network to map state → Q-values for all actions.
- Famous for beating many Atari games from raw pixels.
Key tricks:
- Experience replay: store past experiences and sample them randomly to train more stably.
- Target networks: use a slowly updated copy of the network as a stable target.
2. Policy Gradient Methods
Instead of learning Q-values, these learn the policy directly.
- The network outputs a probability distribution over actions.
- You adjust the network weights to increase the probability of actions that led to higher rewards.
Examples:
- REINFORCE
- PPO (Proximal Policy Optimization)
- A2C / A3C (Advantage Actor-Critic)
These are especially good for:
- Continuous actions (like steering angles)
- More complex control problems
3. Actor-Critic Methods
Mix of the two ideas:
- Actor: the policy network (chooses actions).
- Critic: the value network (evaluates how good states/actions are).
The critic helps the actor learn faster by telling it how good its decisions were, instead of waiting only on raw returns.
Real-World Uses of Deep Reinforcement Learning
Flashrecall automatically keeps track and reminds you of the cards you don't remember well so you remember faster. Like this :

This isn’t just game-playing nerd stuff. DRL shows up in a lot of places:
- Games: AlphaGo, AlphaZero, Atari, Dota 2, StarCraft II.
- Robotics: teaching robots to walk, grasp, or balance.
- Self-driving: decision-making for lane changes, merging, etc.
- Finance: algorithmic trading strategies (careful, very risky).
- Recommendation systems: optimizing long-term user engagement.
- Operations / logistics: scheduling, routing, resource allocation.
The common pattern: there’s a sequence of decisions, and you care about long-term success, not just instant reward.
Why Is Deep Reinforcement Learning So Hard to Learn?
You’ve probably noticed: DRL is conceptually cool but kind of a brain-melter.
Common struggles:
- Tons of new terms: policy, value function, Q-learning, Bellman equation, on/off-policy, exploration vs exploitation.
- Math-heavy papers: expectations, gradients, Markov decision processes (MDPs).
- Algorithms that sound similar but are slightly different.
This is where having a structured system to actually remember stuff matters way more than just reading blog posts.
How to Actually Learn Deep Reinforcement Learning Without Forgetting Everything
Here’s a simple approach that works way better than just watching videos:
1. Get the big picture first
Understand the story: agent, environment, rewards, policy, value.
2. Turn key ideas into questions
Instead of just reading “The Bellman equation is…”, make a flashcard:
- Front: “What is the Bellman equation for the state-value function?”
- Back: The formula + a one-line explanation.
3. Use active recall + spaced repetition
This combo is insanely effective for technical topics like deep reinforcement learning.
And this is exactly where Flashrecall comes in.
Using Flashrecall to Master Deep Reinforcement Learning
Flashrecall (https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085) is a flashcard app that actually makes this stuff stick without you having to micromanage your study schedule.
Here’s how it helps with DRL:
1. Turn Dense Resources Into Flashcards Instantly
Reading a PDF or watching a lecture on DQN or PPO?
With Flashrecall, you can:
- Import PDFs and auto-generate flashcards from the content.
- Paste text from articles or lecture notes and get cards made for you.
- Use YouTube links to pull key info and turn it into cards.
- Add images (like diagrams of neural networks or RL loops) and create cards around them.
- Create cards from audio or just typed prompts.
You can still make cards manually if you’re picky, but the auto-generation saves a ton of time.
2. Built-In Active Recall and Spaced Repetition
You don’t have to remember when to review “Bellman optimality equation” versus “policy gradient theorem.”
Flashrecall:
- Uses spaced repetition automatically.
- Schedules reviews for you based on how well you remember each card.
- Sends study reminders so you don’t fall off the wagon.
So concepts like:
- “What’s the difference between on-policy and off-policy methods?”
- “What problem does experience replay solve in DQN?”
- “What’s the intuition behind the discount factor gamma?”
…keep popping up right before you’re about to forget them.
3. Chat With Your Flashcards When You’re Confused
This is super handy for deep reinforcement learning because the intuition can be tricky.
With Flashrecall, you can:
- Chat with your flashcards if something doesn’t click.
- Ask follow-up questions like:
- “Explain the Bellman equation in simpler words.”
- “Give me an example of exploration vs exploitation.”
- “How is PPO different from vanilla policy gradients?”
It’s like having a study buddy built into your flashcard deck.
4. Study Anywhere (Even Offline)
DRL terms and equations are the kind of thing you want to review in short bursts:
- On the bus
- Between classes
- During a break at work
Flashrecall:
- Works on iPhone and iPad
- Works offline, so you can review your DRL deck anywhere.
Perfect for quick reviews of:
- Key algorithms (DQN, PPO, A3C, SAC, etc.)
- Important equations
- Definitions and differences between methods
5. Great for Exams, Courses, and Self-Study
Doesn’t matter if you’re:
- Taking a university course in reinforcement learning
- Doing a MOOC (like DeepMind’s RL course or a Coursera specialization)
- Reading Sutton & Barto or DRL papers on your own
You can build decks like:
- “RL Foundations” – states, actions, rewards, MDPs, Bellman equation.
- “Value-Based Methods” – Q-learning, SARSA, DQN, target networks, replay buffers.
- “Policy Gradient & Actor-Critic” – policy gradient theorem, advantage function, PPO, A2C/A3C.
- “Applications” – robotics, games, recommender systems examples.
Flashrecall is free to start, fast, and modern, so you won’t feel like you’re using some clunky old tool while studying cutting-edge AI.
Example Deep Reinforcement Learning Flashcards You Could Make
To make this super concrete, here are some card ideas:
- Front: What is deep reinforcement learning?
- Front: What problem does experience replay solve in DQN?
- Front: What’s the difference between on-policy and off-policy RL?
- Front: Intuition behind the discount factor γ (gamma)?
You can throw all of these into Flashrecall, let spaced repetition handle the scheduling, and just focus on understanding.
Final Thoughts
Deep reinforcement learning is basically: an agent, a reward signal, and a deep neural network learning to make smarter decisions over time by trial and error. The ideas themselves are super cool, but they stack up quickly and are easy to forget if you don’t review them properly.
If you actually want this stuff to stick in your brain, pair your videos and textbooks with a solid flashcard system. Flashrecall (https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085) gives you:
- Instant flashcard creation from your DRL resources
- Built-in active recall and spaced repetition
- Study reminders and offline access
- The ability to chat with your cards when concepts feel fuzzy
Learn the theory once, then let your flashcards handle the repetition so you don’t have to keep “relearning” deep reinforcement learning every few weeks.
Frequently Asked Questions
What's the fastest way to create flashcards?
Manually typing cards works but takes time. Many students now use AI generators that turn notes into flashcards instantly. Flashrecall does this automatically from text, images, or PDFs.
Is there a free flashcard app?
Yes. Flashrecall is free and lets you create flashcards from images, text, prompts, audio, PDFs, and YouTube videos.
How can I study more effectively for this test?
Effective exam prep combines active recall, spaced repetition, and regular practice. Flashrecall helps by automatically generating flashcards from your study materials and using spaced repetition to ensure you remember everything when exam day arrives.
Related Articles
- A To Z Flashcards: The Ultimate Guide To Learning Anything Faster From Zero To Expert – Discover How Smart Digital A–Z Cards Can Help You Remember More In Less Time
- Anki 101: The Complete Beginner’s Guide To Smarter Flashcards (And A Faster Alternative Most Students Don’t Know) – Learn how Anki 101 works, where it falls short, and the easier app that gives you the same memory boost with way less hassle.
- Ankitects: The Complete Beginner’s Guide To Smarter Flashcards And Faster Learning – Why Most Students Switch Apps After Trying This
FlashRecall app preview
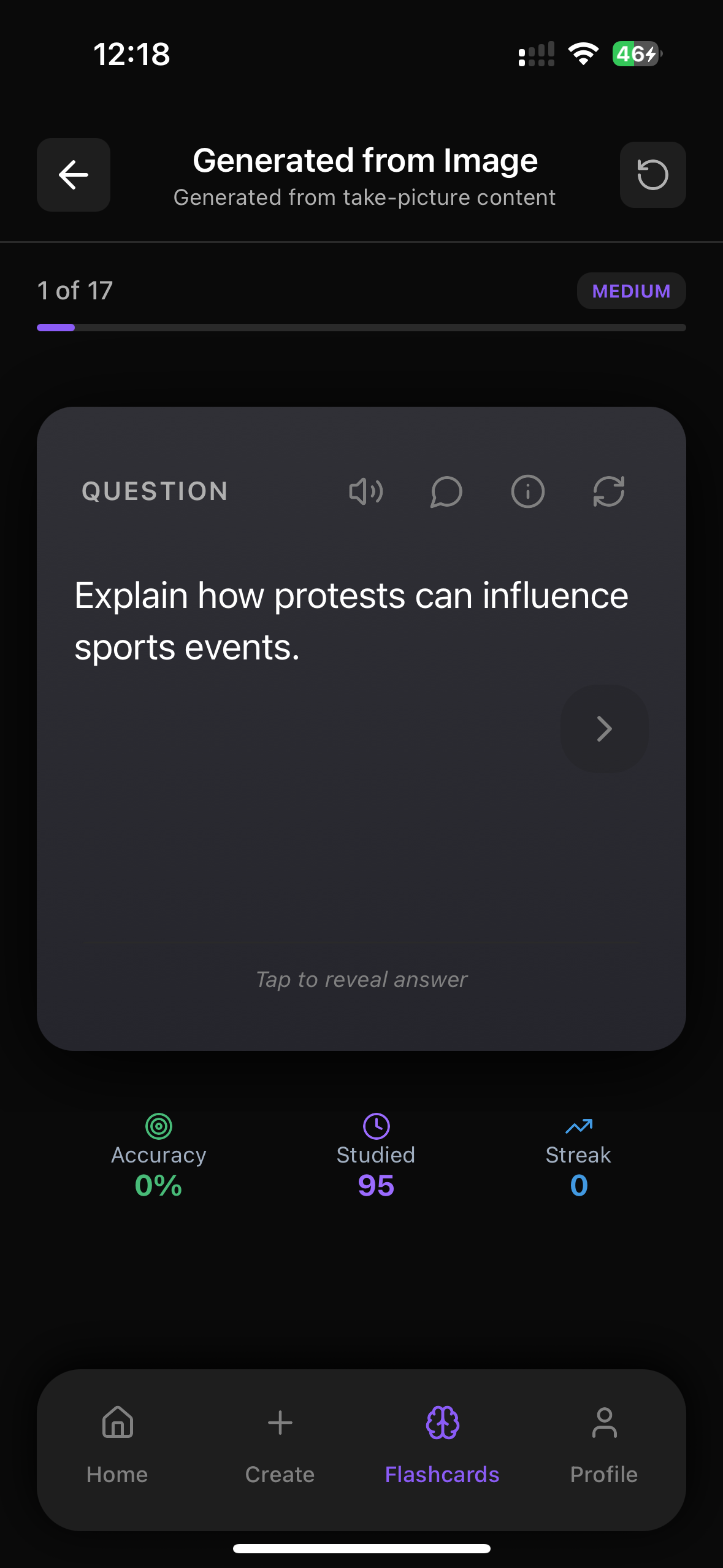
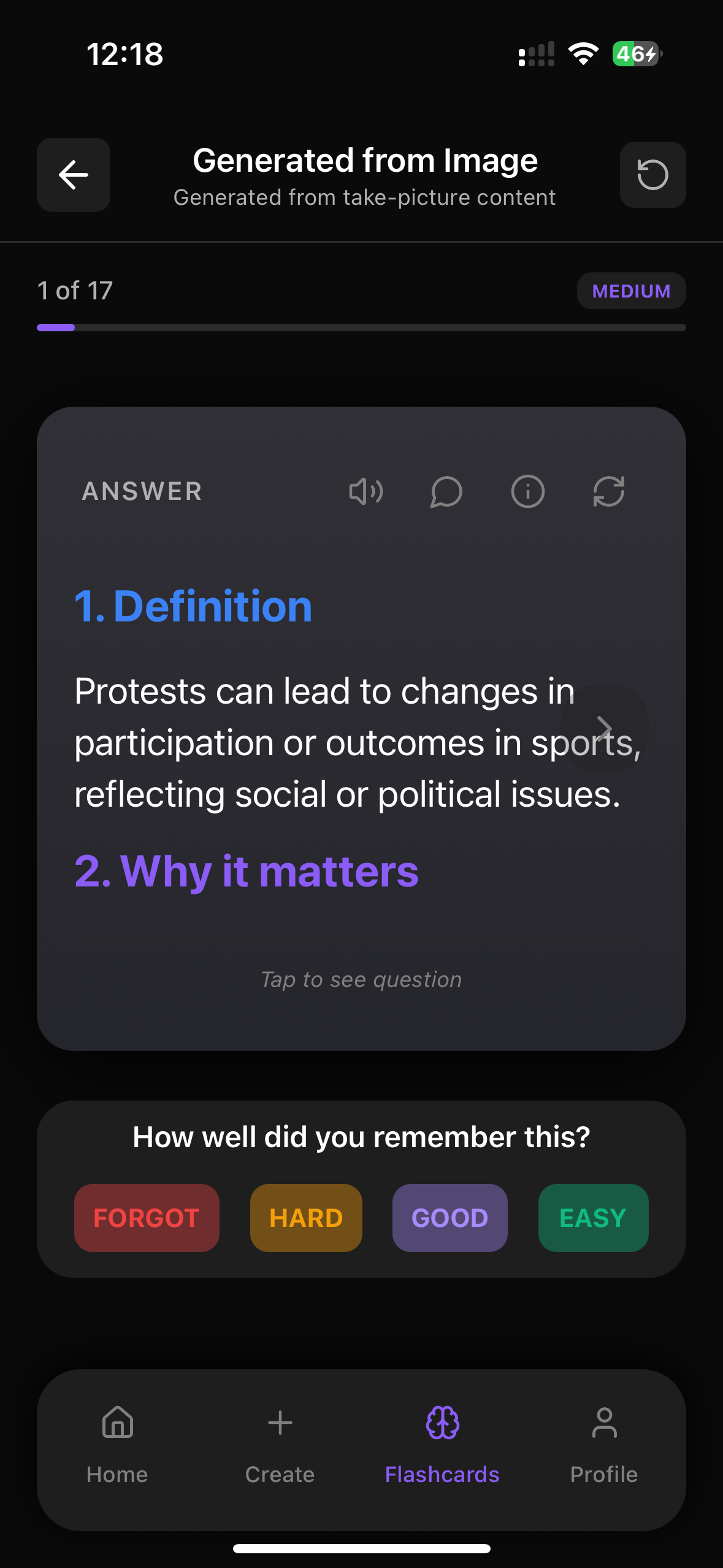
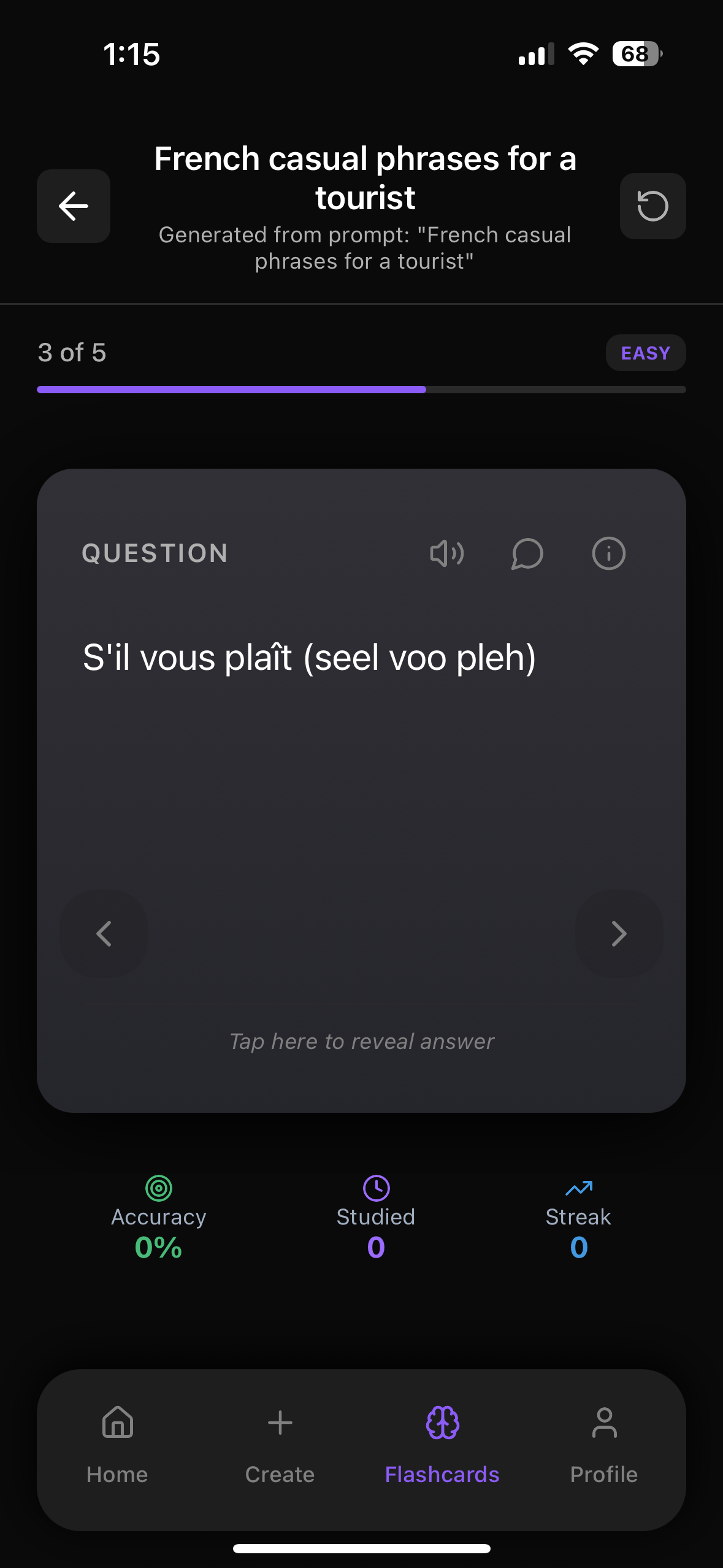
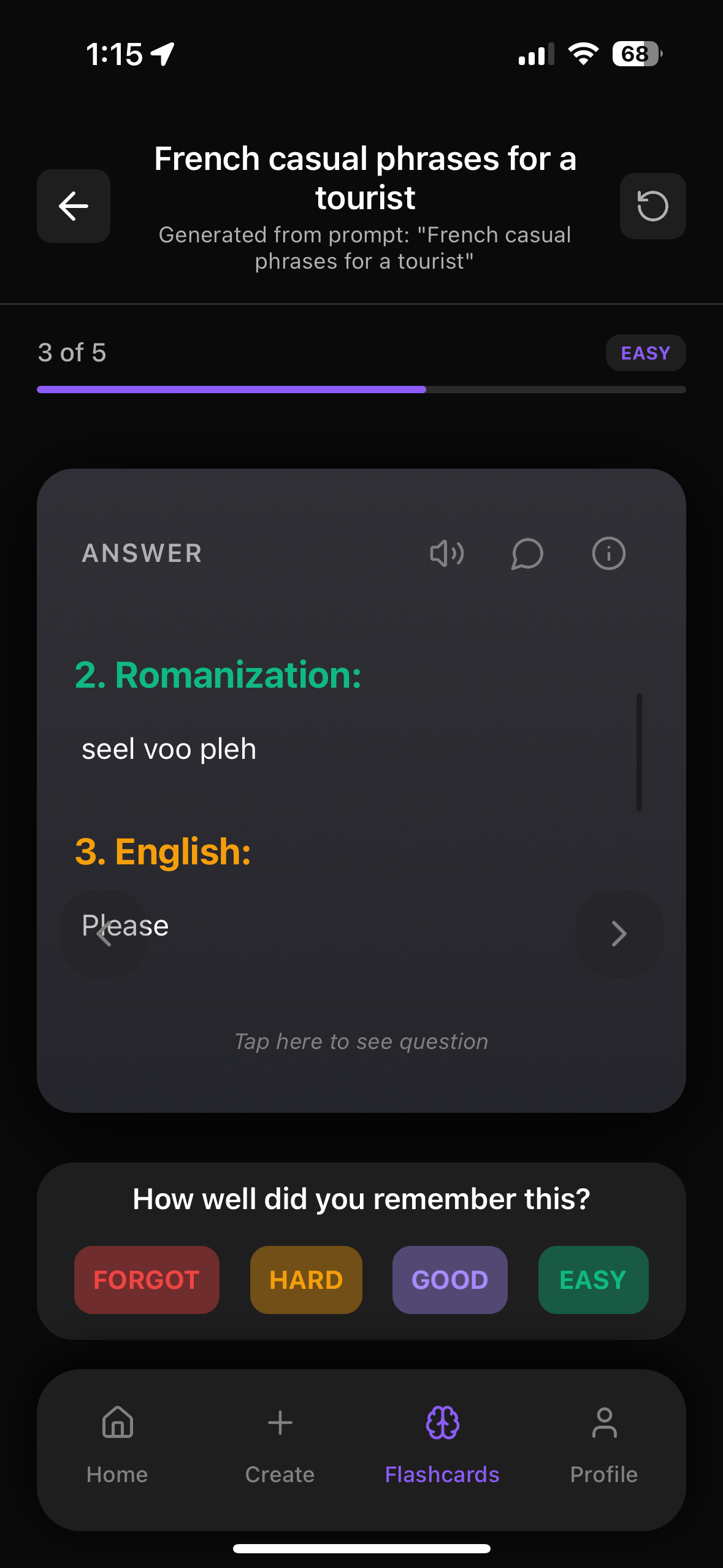
Practice This With Web Flashcards
Try our web flashcards right now to test yourself on what you just read. You can click to flip cards, move between questions, and see how much you really remember.
Try Flashcards in Your BrowserInside the FlashRecall app you can also create your own decks from images, PDFs, YouTube, audio, and text, then use spaced repetition to save your progress and study like top students.
Research References
The information in this article is based on peer-reviewed research and established studies in cognitive psychology and learning science.
Cepeda, N. J., Pashler, H., Vul, E., Wixted, J. T., & Rohrer, D. (2006). Distributed practice in verbal recall tasks: A review and quantitative synthesis. Psychological Bulletin, 132(3), 354-380
Meta-analysis showing spaced repetition significantly improves long-term retention compared to massed practice
Carpenter, S. K., Cepeda, N. J., Rohrer, D., Kang, S. H., & Pashler, H. (2012). Using spacing to enhance diverse forms of learning: Review of recent research and implications for instruction. Educational Psychology Review, 24(3), 369-378
Review showing spacing effects work across different types of learning materials and contexts
Kang, S. H. (2016). Spaced repetition promotes efficient and effective learning: Policy implications for instruction. Policy Insights from the Behavioral and Brain Sciences, 3(1), 12-19
Policy review advocating for spaced repetition in educational settings based on extensive research evidence
Karpicke, J. D., & Roediger, H. L. (2008). The critical importance of retrieval for learning. Science, 319(5865), 966-968
Research demonstrating that active recall (retrieval practice) is more effective than re-reading for long-term learning
Roediger, H. L., & Butler, A. C. (2011). The critical role of retrieval practice in long-term retention. Trends in Cognitive Sciences, 15(1), 20-27
Review of research showing retrieval practice (active recall) as one of the most effective learning strategies
Dunlosky, J., Rawson, K. A., Marsh, E. J., Nathan, M. J., & Willingham, D. T. (2013). Improving students' learning with effective learning techniques: Promising directions from cognitive and educational psychology. Psychological Science in the Public Interest, 14(1), 4-58
Comprehensive review ranking learning techniques, with practice testing and distributed practice rated as highly effective

FlashRecall Team
FlashRecall Development Team
The FlashRecall Team is a group of working professionals and developers who are passionate about making effective study methods more accessible to students. We believe that evidence-based learning tec...
Credentials & Qualifications
- •Software Development
- •Product Development
- •User Experience Design
Areas of Expertise
Try FlashRecall on iPhone
Free tier after signup. AI flashcards from your notes, spaced repetition, and optional paid upgrade when you need more.
Download on App Store