
Reinforcement Learning Python: The Complete Beginner’s Guide To
Reinforcement learning python broken down with agents, rewards, policies, and a Q-learning example in simple code. Plus a neat way to turn it all into.
Want AI flashcards + spaced repetition on iPhone? FlashRecall is free to start (signup required; paid plans optional).
What Is Reinforcement Learning In Python (In Plain English)?
Alright, let’s talk about this. Reinforcement learning Python basically means using Python to build agents that learn by trial and error: they take actions, get rewards, and slowly figure out what works best over time. Instead of being told the correct answer like in normal supervised learning, the model experiments and improves its strategy based on feedback. Think: a bot learning to play a game, a robot learning to walk, or an algorithm learning to trade. And if you’re trying to actually remember all these concepts and code patterns, an app like Flashrecall (https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085) is perfect for turning RL theory and code into flashcards you’ll actually remember.
Quick Overview: How Reinforcement Learning Works
Let’s break it down super simply.
In reinforcement learning (RL), you usually have:
- Agent – the learner/decision maker (your algorithm)
- Environment – the world it interacts with (a game, a grid, a simulator)
- State – what the world looks like right now (position, score, features)
- Action – what the agent can do (move left/right, buy/sell, etc.)
- Reward – a number saying how good that action was (positive or negative)
- Policy – the strategy: given a state, what action should I take?
The agent’s goal: maximize total reward over time.
Python is perfect for this because:
- Tons of RL libraries (Gymnasium, Stable-Baselines3, RLlib, etc.)
- Easy to prototype
- Huge community and tutorials
If you’re learning all these terms and feel like they’re slipping out of your brain every day, that’s exactly where Flashrecall helps: you throw “state, action, reward, policy, value function, Q-function” into flashcards and review them with spaced repetition until they’re automatic.
Why Python Is So Popular For Reinforcement Learning
Here’s why everyone says “reinforcement learning Python” and not, say, “reinforcement learning C++”:
1. Libraries everywhere
- `gymnasium` (formerly OpenAI Gym) for RL environments
- `stable-baselines3` for ready-made RL algorithms
- `numpy`, `pandas`, `matplotlib` for data and plotting
- `pytorch` or `tensorflow` for deep RL
2. Easy to read and write
When you’re already fighting with RL concepts, you don’t want to also fight the language syntax.
3. Tons of examples
Almost every RL tutorial, GitHub repo, or course uses Python.
If you’re going through multiple libraries and tutorials, Flashrecall can be your “memory glue”:
- Save code snippets as flashcards
- Snap screenshots of diagrams and let it auto-make cards
- Paste explanations from docs and turn them into Q&A cards
Link again so you don’t scroll: https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Classic Example: Q-Learning In Python
Let’s look at a super classic RL algorithm: Q-learning.
Idea:
- The agent learns a Q-value for each (state, action) pair: “how good is it if I do this action in this state?”
- It updates these values as it explores.
A tiny, simplified Q-learning skeleton in Python might look like this:
```python
import numpy as np
import random
num_states = 10
num_actions = 2 # e.g. left or right
Q = np.zeros((num_states, num_actions))
alpha = 0.1 # learning rate
gamma = 0.99 # discount factor
epsilon = 0.1 # exploration rate
def choose_action(state):
if random.random() < epsilon:
return random.randint(0, num_actions - 1) # explore
return np.argmax(Q[state]) # exploit
for episode in range(1000):
state = 0 # reset environment
done = False
while not done:
action = choose_action(state)
here you'd interact with your environment:
next_state, reward, done = env.step(action)
for demo:
next_state = min(state + 1, num_states - 1)
reward = 1 if next_state == num_states - 1 else 0
done = (next_state == num_states - 1)
old_value = Q[state, action]
next_max = np.max(Q[next_state])
Q-learning update rule
Q[state, action] = old_value + alpha (reward + gamma next_max - old_value)
state = next_state
```
Flashrecall automatically keeps track and reminds you of the cards you don't remember well so you remember faster. Like this :

You don’t have to fully understand this yet, but here’s what you should remember:
- What Q is
- The meaning of alpha, gamma, epsilon
- The update rule
Perfect flashcard material.
Example Flashrecall cards you could make:
- Q: What does gamma (γ) represent in Q-learning?
- Q: Write the Q-learning update rule.
You can literally paste that formula into Flashrecall and quiz yourself on it each day.
Deep Reinforcement Learning With Python
Once you get the basic RL ideas, you’ll see Deep Q-Networks (DQN) and other deep RL methods everywhere.
Here’s the difference:
- Q-learning: Q-values stored in a table → good for small state spaces.
- DQN: Q-values approximated by a neural network → works for large/continuous state spaces (like images, complex games).
Typical deep RL stack in Python:
- Environment: `gymnasium` (Atari games, CartPole, etc.)
- Neural nets: `pytorch` or `tensorflow/keras`
- Algorithms: You can write your own or use `stable-baselines3` (PPO, A2C, DQN, etc.)
When you’re learning deep RL, you suddenly have:
- RL concepts
- Neural network concepts
- Hyperparameters
- Tons of new acronyms (PPO, A2C, SAC, TD3…)
This is where most people get overwhelmed and forget stuff week to week. Flashrecall helps you build a personal “RL dictionary” in your pocket.
You can:
- Turn YouTube lectures into cards by dropping the link and extracting key points
- Import notes or PDFs from courses and auto-generate flashcards
- Add images of network architectures and label them
And then spaced repetition in the app keeps resurfacing what you’re about to forget.
Simple Roadmap To Learn Reinforcement Learning With Python
Here’s a no-BS path you can follow:
1. Get Comfortable With Python Basics
You should be okay with:
- Functions
- Loops
- Classes (helpful but not mandatory at first)
- `numpy` arrays
Make a tiny set of Flashrecall cards for:
- `numpy` operations you always Google
- Common Python quirks (list vs numpy array, slicing, etc.)
2. Learn Core RL Concepts (Without Code First)
Understand these in words:
- Agent, environment, state, action, reward
- Policy
- Value function vs Q-function
- Exploration vs exploitation
Dump each term into Flashrecall as:
- One card per concept
- One card comparing similar ideas (e.g., value function vs Q-function)
Because Flashrecall has built-in active recall, it’ll push you to answer from memory instead of just rereading definitions.
3. Implement A Tiny Q-Learning Example
Use a super simple environment:
- Gridworld
- 1D line like the example above
- Or CartPole from `gymnasium`
Key goal: understand the loop:
- Observe state
- Choose action
- Get reward + next state
- Update Q or network
Turn each step into flashcards:
- “What are the main steps of the RL loop?”
- “What is epsilon-greedy exploration?”
4. Move To A Library Like Stable-Baselines3
Instead of coding everything from scratch, use:
```bash
pip install stable-baselines3[extra] gymnasium
```
Then a tiny example:
```python
import gymnasium as gym
from stable_baselines3 import PPO
env = gym.make("CartPole-v1")
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000)
obs, _ = env.reset()
for _ in range(1000):
action, _states = model.predict(obs)
obs, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
obs, _ = env.reset()
```
Flashcards to remember:
- What PPO stands for
- When to use policy gradient methods vs value-based methods
- Common hyperparameters (learning rate, batch size, etc.)
How To Actually Remember RL Concepts (Instead Of Relearning Them)
This is the part people skip: memory.
RL is super concept-heavy. If you don’t review, you’ll forget:
- The difference between on-policy and off-policy
- What TD(0) means
- Why discounting exists
- How the Bellman equation works
Flashrecall helps here because it bakes in two powerful ideas:
- Active recall – you’re forced to answer from memory before seeing the answer
- Spaced repetition – it schedules reviews right before you forget
With Flashrecall (iPhone & iPad):
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
You can:
- Make flashcards manually for formulas, definitions, and code patterns
- Instantly generate cards from:
- Text (copy-paste from docs or notes)
- PDFs (RL papers, lecture slides)
- Images (photos of whiteboards or slides)
- YouTube links (RL course videos)
- Typed prompts (ask it to turn your notes into Q&A cards)
- Study offline when you’re commuting or away from your laptop
- Get auto reminders so you don’t have to remember when to review
You can even chat with your flashcards if you’re unsure about something, like:
> “Explain the difference between Q-learning and SARSA again but simpler.”
That’s insanely useful when you’re stuck on some RL nuance at 11pm.
Example Flashcard Set For “Reinforcement Learning Python”
Here’s a mini set you could build in Flashrecall:
1. Concepts
- Q: What is a Markov Decision Process (MDP)?
A: A formal framework for RL with states, actions, transition probabilities, rewards, and a discount factor.
- Q: What’s the goal of an RL agent?
A: Maximize expected cumulative reward over time.
2. Algorithms
- Q: Difference between Q-learning and SARSA?
A: Q-learning is off-policy (uses max over next actions), SARSA is on-policy (uses the next action actually taken).
3. Python / Libraries
- Q: What does `env.step(action)` return in Gymnasium?
A: `(obs, reward, terminated, truncated, info)`.
- Q: What is Stable-Baselines3 used for?
A: Implementing RL algorithms (PPO, A2C, DQN, etc.) easily in Python.
4. Formulas
- Q: Q-learning update rule?
A: Q(s,a) ← Q(s,a) + α [r + γ maxₐ' Q(s',a') − Q(s,a)]
You toss these into Flashrecall once, and the app handles the spaced repetition with auto reminders, so you just open it when it tells you to.
Final Thoughts
If you’re diving into reinforcement learning Python, the winning combo is:
- Learn the core ideas slowly and clearly
- Implement small experiments in Python
- Use spaced repetition to keep everything in your head long-term
Flashrecall makes that last step way easier by turning your RL notes, screenshots, PDFs, and code into smart flashcards that you review at the right time:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Do the coding in Python, let RL do the learning in your environment, and let Flashrecall handle the learning in your brain.
Frequently Asked Questions
What's the fastest way to create flashcards?
Manually typing cards works but takes time. Many students now use AI generators that turn notes into flashcards instantly. Flashrecall does this automatically from text, images, or PDFs.
Is there a free flashcard app?
Yes. Flashrecall is free and lets you create flashcards from images, text, prompts, audio, PDFs, and YouTube videos.
How can I study more effectively for this test?
Effective exam prep combines active recall, spaced repetition, and regular practice. Flashrecall helps by automatically generating flashcards from your study materials and using spaced repetition to ensure you remember everything when exam day arrives.
Related Articles
- Cozmo Coding: The Complete Beginner’s Guide To Teaching Kids Real Programming Skills Fast – Learn How To Turn Playtime With Cozmo Into Powerful STEM Learning Most Parents Miss
- Flashcards From PDF: The Complete Guide To Turning Any Document Into Powerful Study Cards Fast – Stop Copy-Pasting And Start Learning Smarter Today
- Google Play Academy Study Jam: Complete Guide To Learning Faster (And Actually Remembering Stuff) – Learn how to turn every Study Jam into long‑term knowledge with smart flashcards and spaced repetition.
FlashRecall app preview
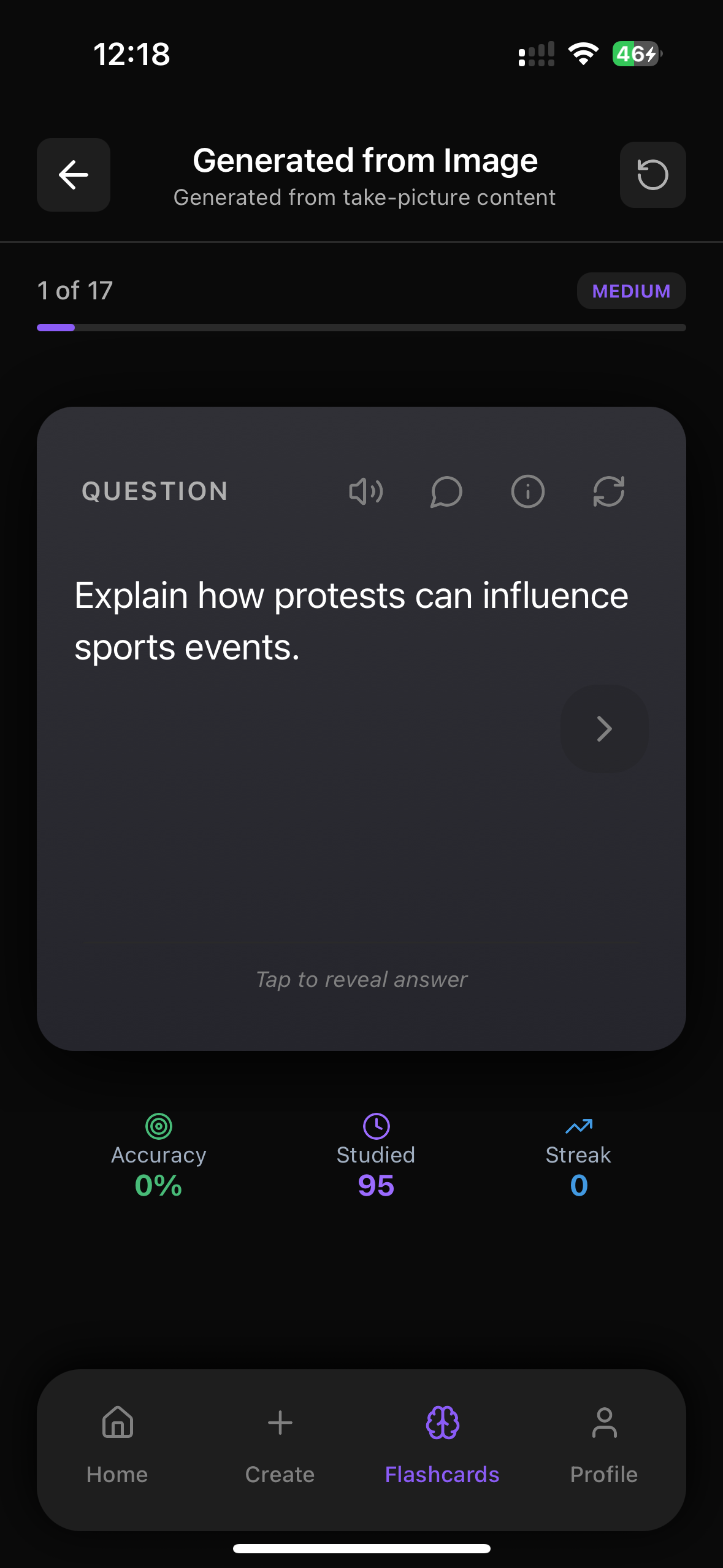
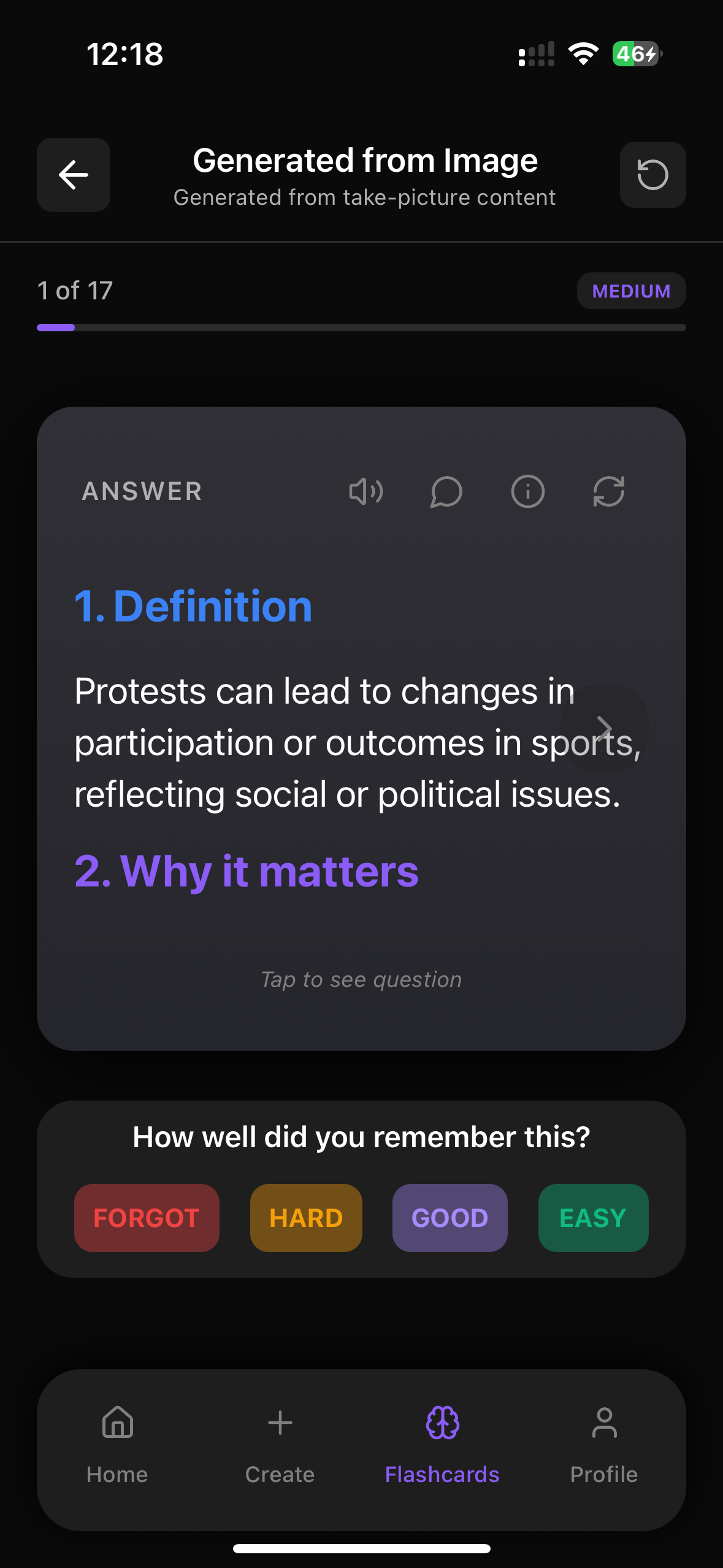
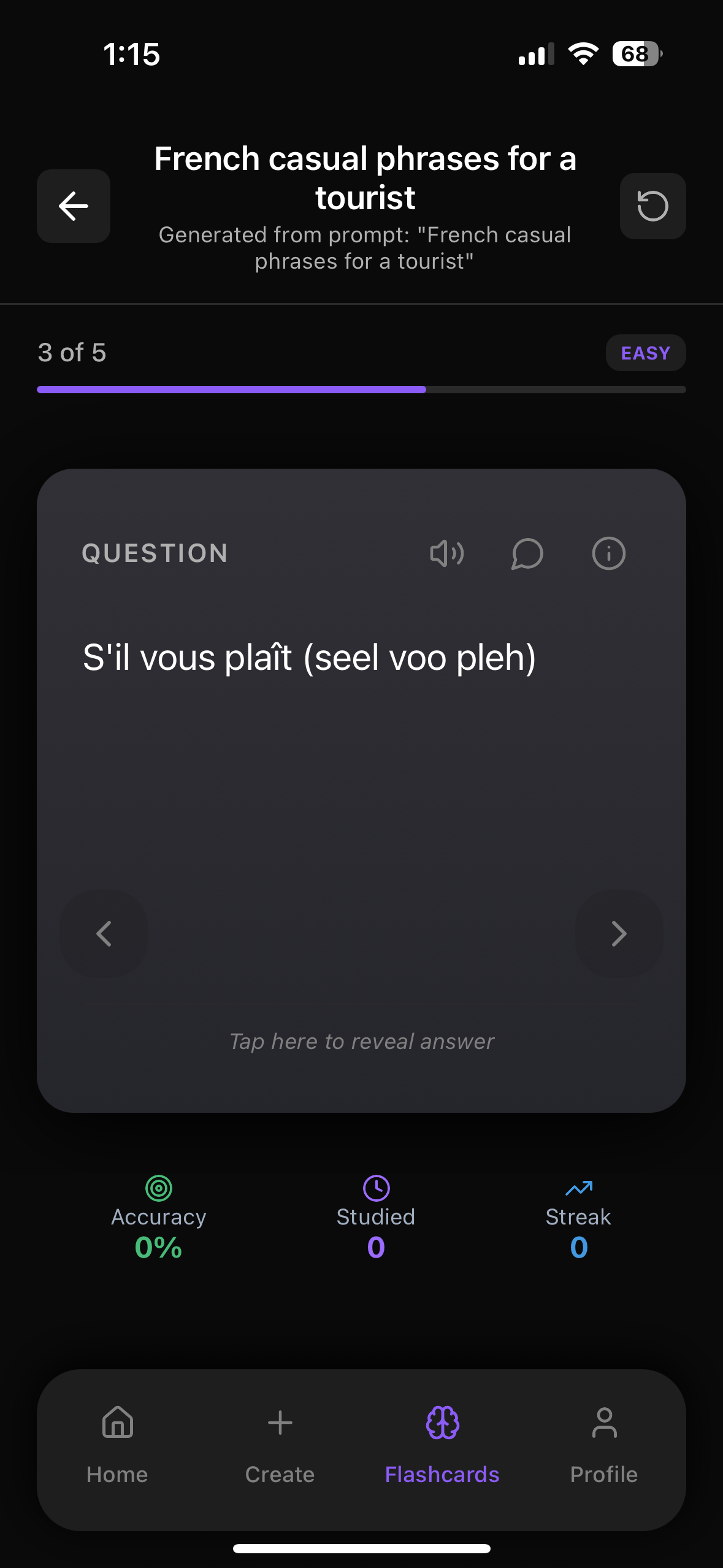
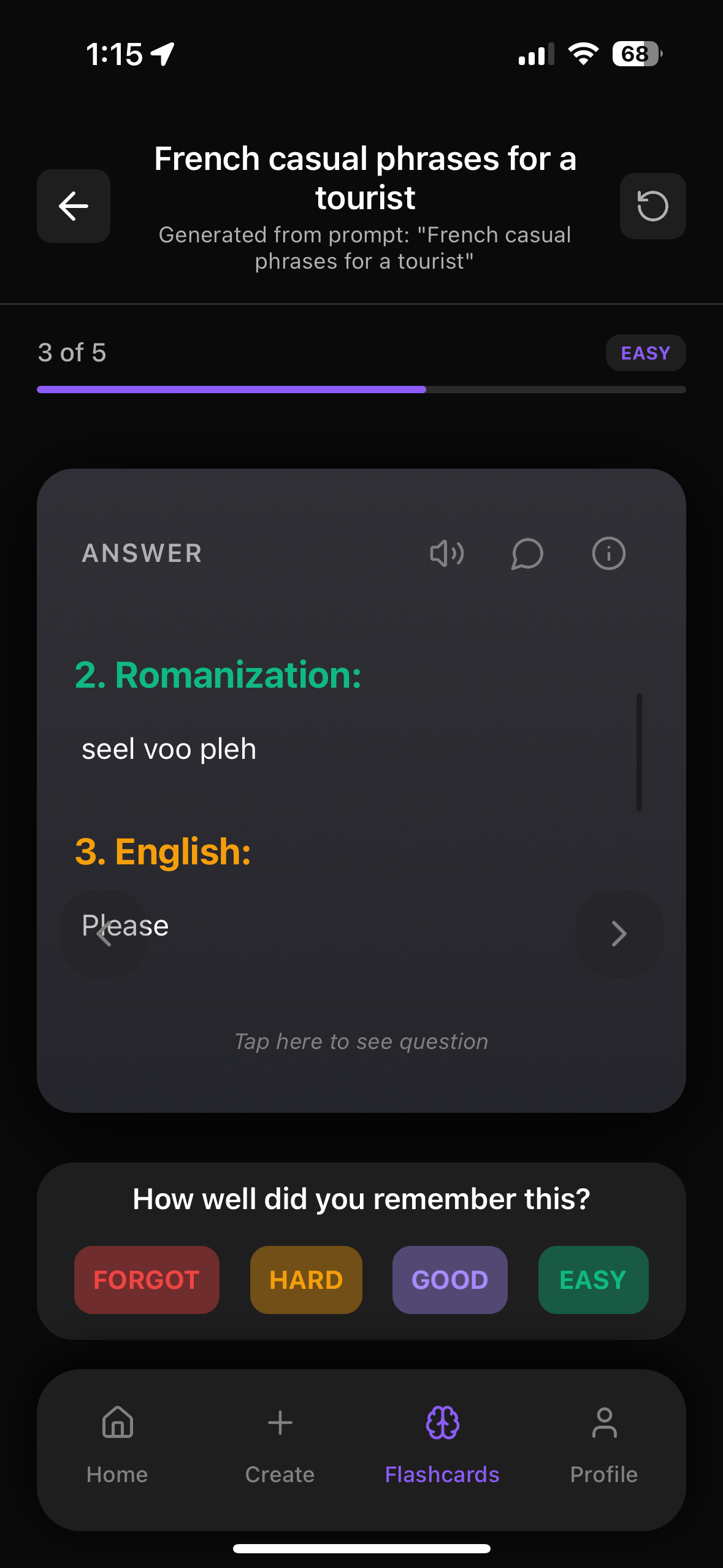
Practice This With Web Flashcards
Try our web flashcards right now to test yourself on what you just read. You can click to flip cards, move between questions, and see how much you really remember.
Try Flashcards in Your BrowserInside the FlashRecall app you can also create your own decks from images, PDFs, YouTube, audio, and text, then use spaced repetition to save your progress and study like top students.
Research References
The information in this article is based on peer-reviewed research and established studies in cognitive psychology and learning science.
Cepeda, N. J., Pashler, H., Vul, E., Wixted, J. T., & Rohrer, D. (2006). Distributed practice in verbal recall tasks: A review and quantitative synthesis. Psychological Bulletin, 132(3), 354-380
Meta-analysis showing spaced repetition significantly improves long-term retention compared to massed practice
Carpenter, S. K., Cepeda, N. J., Rohrer, D., Kang, S. H., & Pashler, H. (2012). Using spacing to enhance diverse forms of learning: Review of recent research and implications for instruction. Educational Psychology Review, 24(3), 369-378
Review showing spacing effects work across different types of learning materials and contexts
Kang, S. H. (2016). Spaced repetition promotes efficient and effective learning: Policy implications for instruction. Policy Insights from the Behavioral and Brain Sciences, 3(1), 12-19
Policy review advocating for spaced repetition in educational settings based on extensive research evidence
Karpicke, J. D., & Roediger, H. L. (2008). The critical importance of retrieval for learning. Science, 319(5865), 966-968
Research demonstrating that active recall (retrieval practice) is more effective than re-reading for long-term learning
Roediger, H. L., & Butler, A. C. (2011). The critical role of retrieval practice in long-term retention. Trends in Cognitive Sciences, 15(1), 20-27
Review of research showing retrieval practice (active recall) as one of the most effective learning strategies
Dunlosky, J., Rawson, K. A., Marsh, E. J., Nathan, M. J., & Willingham, D. T. (2013). Improving students' learning with effective learning techniques: Promising directions from cognitive and educational psychology. Psychological Science in the Public Interest, 14(1), 4-58
Comprehensive review ranking learning techniques, with practice testing and distributed practice rated as highly effective

FlashRecall Team
FlashRecall Development Team
The FlashRecall Team is a group of working professionals and developers who are passionate about making effective study methods more accessible to students. We believe that evidence-based learning tec...
Credentials & Qualifications
- •Software Development
- •Product Development
- •User Experience Design
Areas of Expertise
Try FlashRecall on iPhone
Free tier after signup. AI flashcards from your notes, spaced repetition, and optional paid upgrade when you need more.
Download on App Store