
Deep Reinforcement Learning Nanodegree
deep reinforcement learning nanodegree broken down in plain English, plus a simple spaced-repetition workflow so you don’t forget the math, code, or RL tricks.
Want AI flashcards + spaced repetition on iPhone? FlashRecall is free to start (signup required; paid plans optional).
What Even Is A Deep Reinforcement Learning Nanodegree?
Alright, let’s talk about what a deep reinforcement learning nanodegree actually is: it’s an online program (like Udacity’s) that teaches you how to build AI agents that learn by trial and error using neural networks. Instead of just reading theory, you work on hands-on projects like training agents to play games, control robots, or optimize decisions over time. It matters because this is the tech behind things like AlphaGo, game-playing bots, and smart control systems, and it’s way more math-heavy and code-heavy than a normal “ML 101” course. And honestly, the hardest part isn’t signing up for a deep reinforcement learning nanodegree – it’s remembering all the formulas, algorithms, and tricks long enough to actually use them, which is where a good study workflow (and tools like Flashrecall) saves you from drowning.
By the way, if you want a super easy way to remember all the equations, definitions, and PyTorch patterns from the nanodegree, Flashrecall is perfect: it turns text, screenshots, PDFs, and more into flashcards with built-in spaced repetition and active recall:
👉 https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Quick Breakdown: What You Learn In A Deep Reinforcement Learning Nanodegree
Let’s keep it simple. A typical deep reinforcement learning nanodegree usually covers:
- RL basics
- Markov Decision Processes (MDPs)
- States, actions, rewards, policies, value functions
- Value-based methods
- Q-learning
- Deep Q-Networks (DQN) and all the “improvements” (Double DQN, Dueling DQN, Prioritized Replay)
- Policy-based methods
- Policy gradients
- REINFORCE
- Actor-Critic methods
- Advanced algorithms
- A2C / A3C
- PPO, DDPG, TD3, SAC (depending on the program)
- Environments & tools
- OpenAI Gym / Gymnasium
- PyTorch or TensorFlow
- Training agents in games or simulated robotics
Each of these topics comes with:
- New math (gradients, expectations, Bellman equations)
- New code patterns (neural net architectures, replay buffers, training loops)
- New intuition (exploration vs exploitation, stability tricks, reward shaping)
That’s a lot to keep in your head at once. If you just watch videos and “kinda get it”, you’ll forget 80% in a week.
This is exactly where a flashcard system like Flashrecall quietly becomes your best friend in the background.
Why Deep RL Is So Easy To “Understand” Once… And Then Completely Forget
You know that feeling where you watch a lecture on DQN, think “yeah, makes sense”, and then two days later you can’t remember:
- The exact Bellman update
- What goes into the target network
- Or how the replay buffer is actually used in the training loop
That’s not you being bad at math – that’s just your brain doing its normal “delete unused stuff” routine.
Deep RL has three big memory problems:
1. Lots of similar-sounding concepts
- Q-function vs value function vs advantage function
- Policy gradient vs actor-critic vs advantage actor-critic
2. Equations with tiny but important differences
- Bellman equation for value vs Q-value
- On-policy vs off-policy updates
3. Code patterns that look the same but behave differently
- DQN vs Double DQN vs Dueling DQN
- PPO clipping vs vanilla policy gradient
If you don’t review this stuff properly, you’ll end up rewatching lectures instead of building cool projects.
How Flashrecall Fits Into Your Nanodegree Study Workflow
So, here’s how you can plug Flashrecall into your deep reinforcement learning nanodegree without adding extra pain:
👉 App link again so you don’t have to scroll:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
1. Turn Lecture Slides & PDFs Into Cards Instantly
Most nanodegrees give you:
- PDF notes
- Slide decks
- Written lesson summaries
Instead of manually typing everything into flashcards, you can:
- Import PDFs into Flashrecall and let it auto-generate cards
- Screenshot a key slide (like the PPO loss function) and have Flashrecall pull text and make cards from the image
- Paste text directly from the nanodegree content and turn it into questions/answers
You don’t waste energy on formatting – you spend it on actually understanding.
2. Use Active Recall For The Scary Stuff (Math & Algorithms)
Flashrecall is built around active recall – instead of just reading, you’re forced to answer:
Examples of good deep RL cards:
- Q: “Write the Bellman optimality equation for Q*(s, a).”
A: `Q(s,a) = E[ r + γ max_{a’} Q(s’, a’) | s, a ]`
- Q: “What problem does Double DQN try to fix?”
A: Overestimation bias from using the same network to select and evaluate actions.
- Q: “Why do we use a replay buffer in DQN?”
A: To break correlation between consecutive samples and stabilize training.
When you’re forced to recall like this, the math actually sticks.
3. Spaced Repetition So You Don’t Cram Before Projects
Flashrecall automatically keeps track and reminds you of the cards you don't remember well so you remember faster. Like this :

Deep RL ideas build on each other. If you forget policy gradients, actor-critic will feel like a mess.
Flashrecall uses built-in spaced repetition with auto reminders, so:
- You see new cards more often at first
- Older, well-known cards show up less often
- You don’t have to manually track when to review anything
You just open the app, and it tells you exactly what to review that day. No guilt, no “I’ll do it later” spreadsheet.
7 Practical Study Tricks For Your Deep Reinforcement Learning Nanodegree
1. Make Flashcards For Concepts, Not Just Formulas
Don’t just memorize equations; also capture intuition:
- Q: “Intuitively, what does the discount factor γ control in RL?”
A: How much the agent cares about future rewards vs immediate ones.
- Q: “Why is exploration important in RL?”
A: Without exploration, the agent can get stuck in suboptimal behaviors and never discover better actions.
You can type these manually in Flashrecall, or paste from your notes and tweak.
2. Save Your Code Patterns As Cards
Deep RL is super code-heavy. You’ll forget:
- How to structure the training loop
- Where to detach gradients
- How to compute returns or advantages
Use Flashrecall like a mini code snippet brain:
- Paste short PyTorch snippets into the answer field
- Question example: “Basic structure of a DQN training step?”
- Answer: your code snippet with comments
Next time you start a new project, your brain already has the template.
3. Use Screenshots From The Nanodegree Directly
You don’t have to retype everything. Flashrecall can make flashcards from images:
- Take a screenshot of a key diagram (like the actor-critic architecture)
- Import it into Flashrecall
- Add a question: “Explain this diagram in your own words.”
- Answer: your explanation, in text
That way, you’re not just passively looking at diagrams – you’re explaining them back.
4. Turn YouTube & Extra Tutorials Into Cards Too
If you’re supplementing your nanodegree with YouTube videos or blog posts:
- Drop the YouTube link or text into Flashrecall
- Let it help you generate cards from the content
- Clean them up a bit so they match what you understand
You end up with a single, unified memory system for everything deep RL, not scattered bookmarks you never revisit.
5. Use “Chat With The Flashcard” When You’re Stuck
One cool thing: in Flashrecall, you can chat with the flashcard if you don’t fully get something.
Example:
- You see a card about PPO clipping
- You kinda remember, but not fully
- You open chat and ask: “Explain PPO like I’m 12” or “How is PPO different from vanilla policy gradient?”
It’s like having a tutor built into your notes, which is super handy when you’re stuck at some weird part of the nanodegree at 1am.
6. Study In Short, Focused Sessions (With Reminders)
Instead of 3-hour guilt-filled cram sessions, do:
- 15–25 minute Flashrecall sessions
- Once or twice a day
Flashrecall has study reminders, so your phone nudges you:
- “Hey, you’ve got 30 cards due today”
You open it, grind through them, and you’re done. Consistency > intensity.
7. Use It Offline When You’re Away From Your Laptop
Deep RL coding needs your laptop, but reviewing doesn’t.
Flashrecall:
- Works offline
- Runs on iPhone and iPad
- Syncs when you’re back online
So you can review:
- On the train
- In a coffee line
- Before bed
Those tiny pockets of time add up and keep everything fresh.
Why Flashrecall Beats Generic Flashcard Apps For This Kind Of Stuff
You could use a generic flashcard app, but deep RL has some special needs:
- You’re juggling math, code, and intuition
- You’re pulling from PDFs, videos, slides, GitHub repos
- You need something fast and modern, not clunky
Flashrecall fits that nicely because it:
- Makes flashcards instantly from images, text, audio, PDFs, YouTube links, or typed prompts
- Lets you create cards manually when you want full control
- Has built-in active recall + spaced repetition + reminders so you don’t manage anything manually
- Works great for university-level stuff, ML, medicine, business, languages, exams – basically anything complex
- Is free to start, so you can test it alongside your nanodegree without committing
Again, here’s the link so you can grab it now and set it up before your next lesson:
👉 https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Simple Setup Plan For Your Deep RL Nanodegree
If you want a super quick starting plan, do this:
1. After each lesson
- Make 10–20 Flashrecall cards:
- 5 for key definitions (policy, value function, advantage, etc.)
- 5 for equations
- 5–10 for intuition + code patterns
2. Every day
- Open Flashrecall
- Clear your due cards (takes 10–20 minutes)
3. Before each project
- Review cards related to the algorithms you’ll use (e.g., DQN or PPO)
- Add cards for any new tricks you learn during implementation
4. After the nanodegree
- Keep reviewing once or twice a week
- Your deep RL knowledge won’t fade away like most online course content does
Final Thoughts
A deep reinforcement learning nanodegree can absolutely level up your AI skills, but only if you actually remember what you’re learning long-term. Watching videos and coding once isn’t enough – you need a system.
Use the nanodegree for structure and projects.
Use Flashrecall to lock the math, code, and intuition into your brain for good.
Grab it here and set it up before your next lecture:
👉 https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Your future self, trying to remember the difference between DQN and PPO during an interview, will be very thankful.
Frequently Asked Questions
What's the most effective study method?
Research consistently shows that active recall combined with spaced repetition is the most effective study method. Flashrecall automates both techniques, making it easy to study effectively without the manual work.
How can I improve my memory?
Memory improves with active recall practice and spaced repetition. Flashrecall uses these proven techniques automatically, helping you remember information long-term.
What should I know about Reinforcement?
Deep Reinforcement Learning Nanodegree covers essential information about Reinforcement. To master this topic, use Flashrecall to create flashcards from your notes and study them with spaced repetition.
Related Articles
FlashRecall app preview
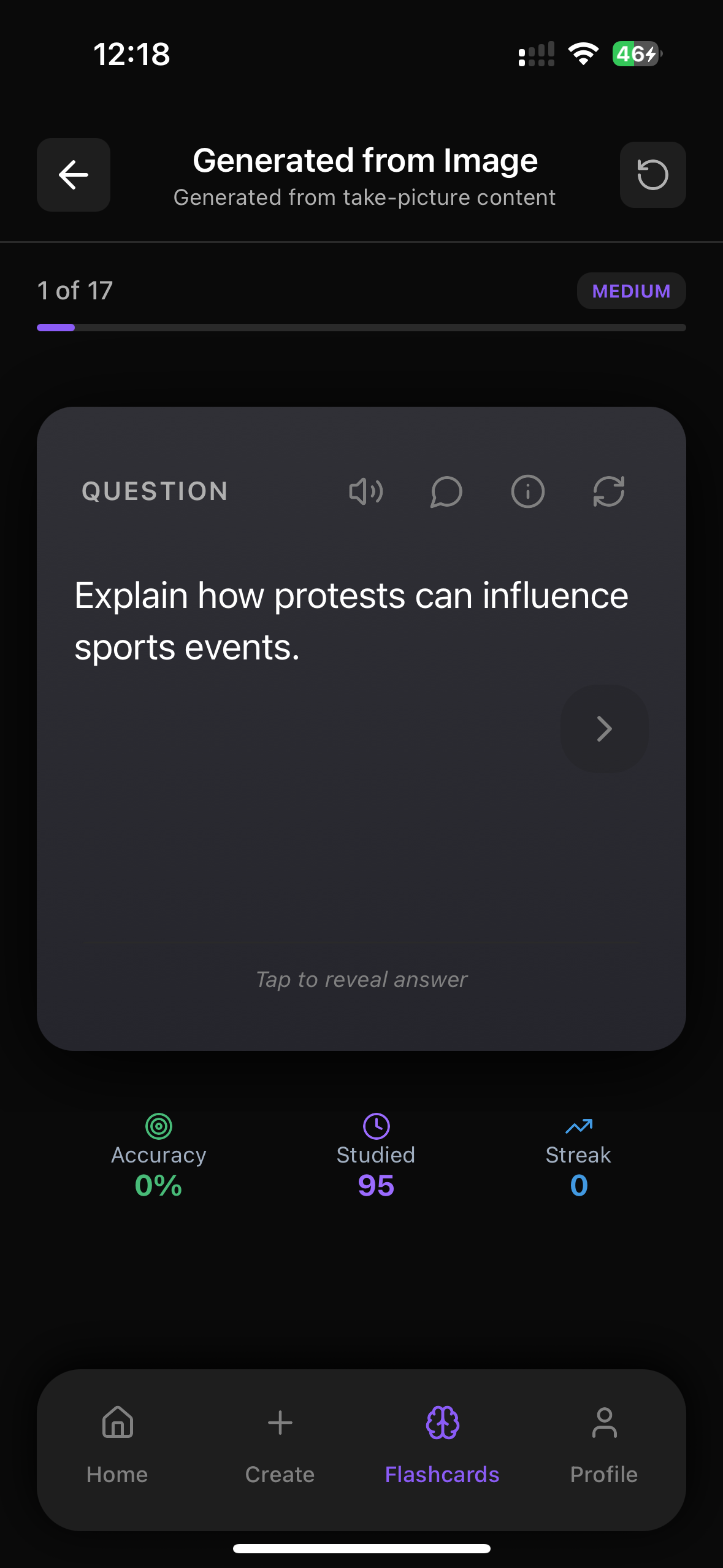
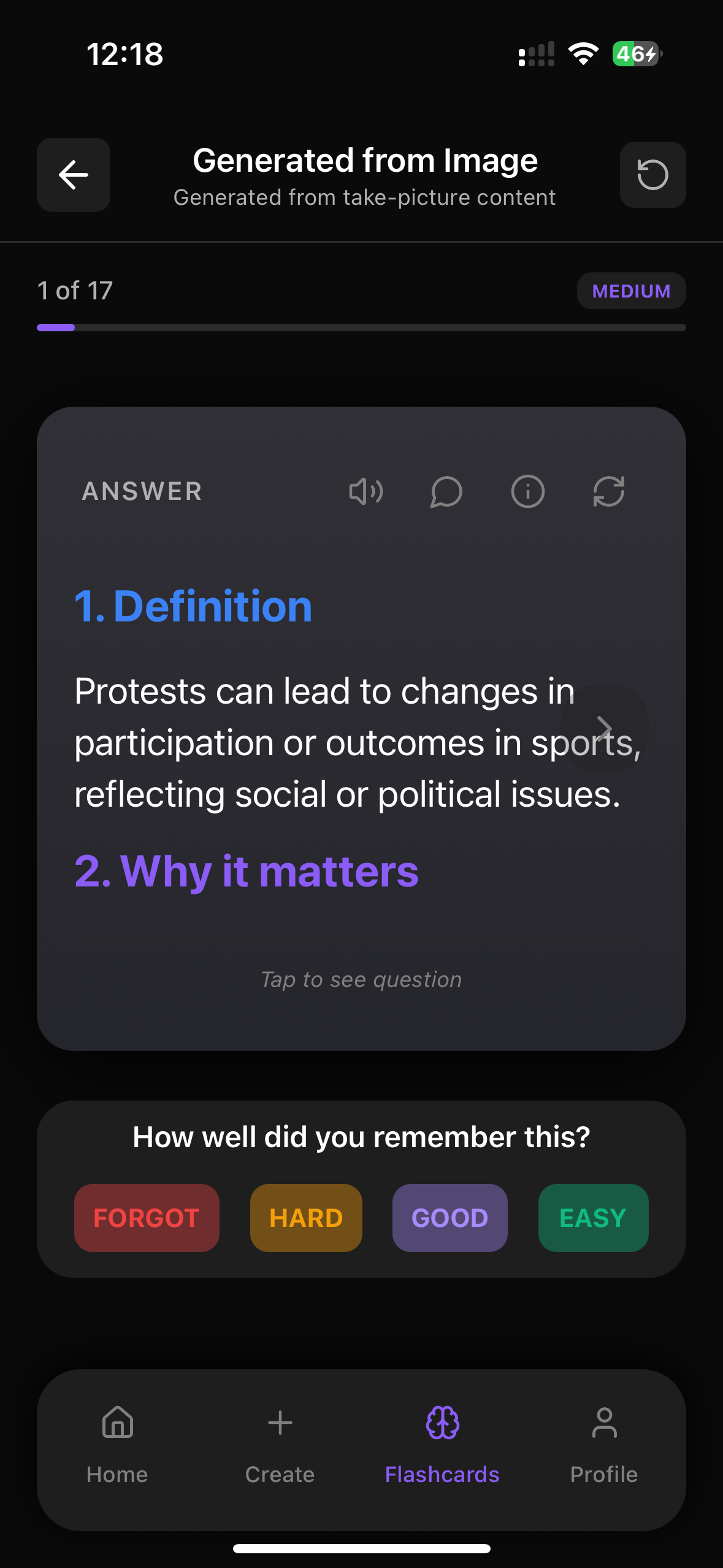
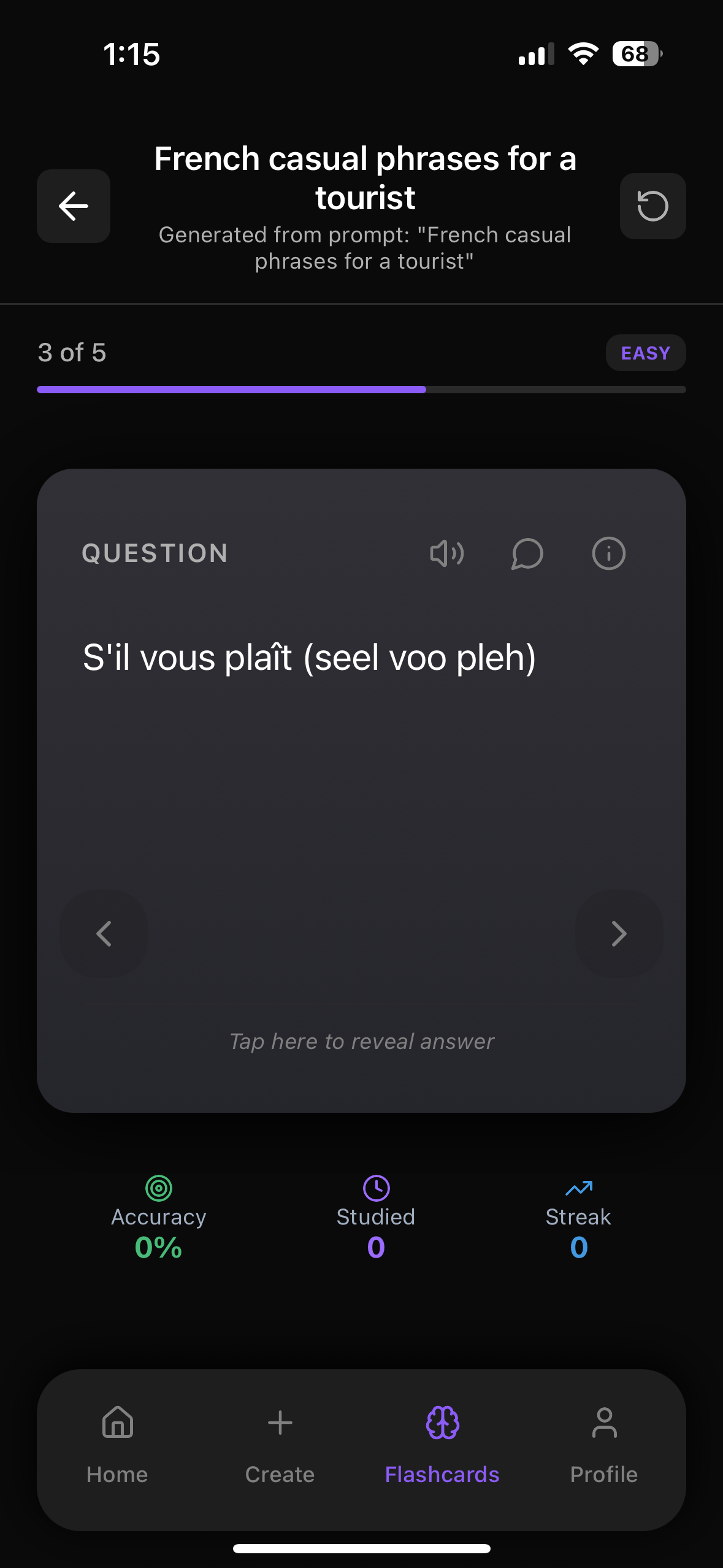
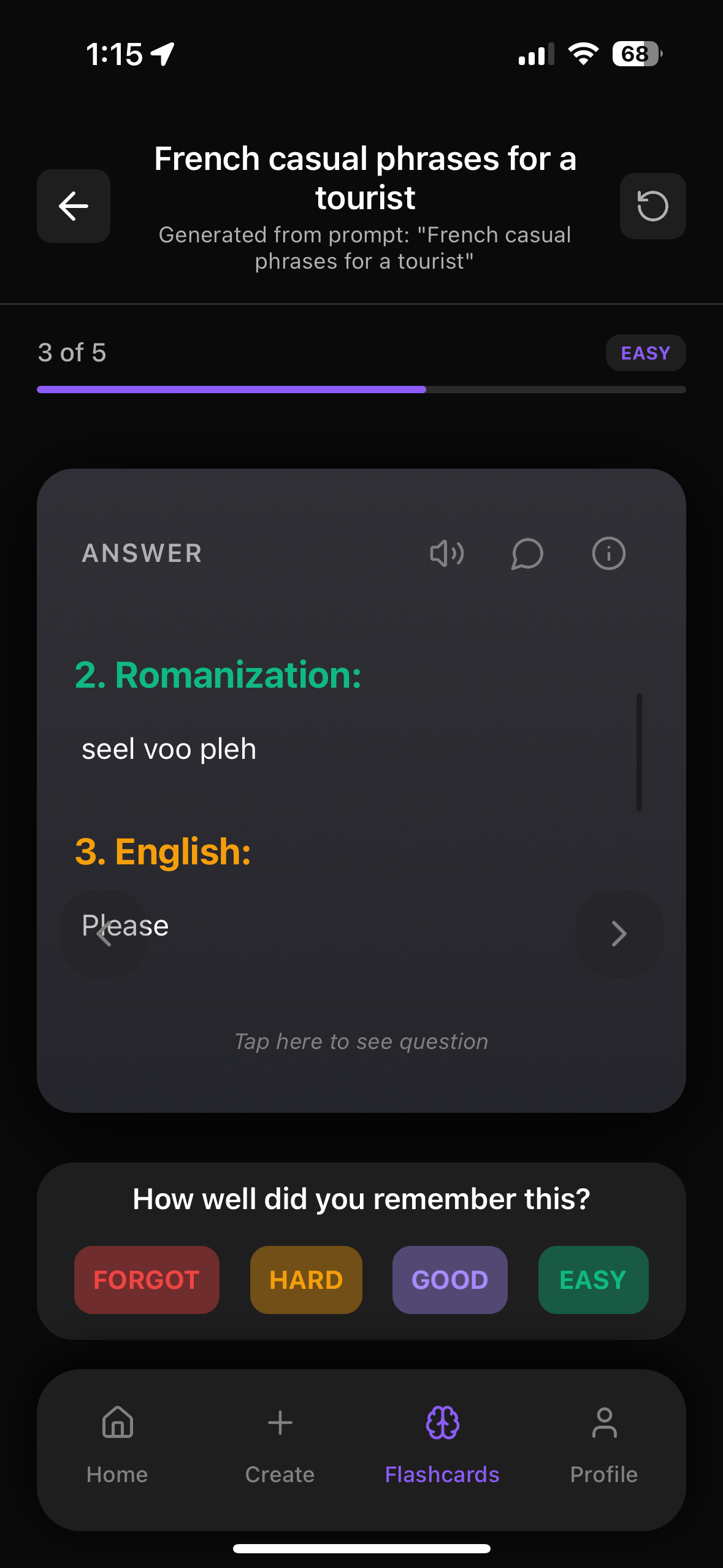
Practice This With Web Flashcards
Try our web flashcards right now to test yourself on what you just read. You can click to flip cards, move between questions, and see how much you really remember.
Try Flashcards in Your BrowserInside the FlashRecall app you can also create your own decks from images, PDFs, YouTube, audio, and text, then use spaced repetition to save your progress and study like top students.
Research References
The information in this article is based on peer-reviewed research and established studies in cognitive psychology and learning science.
Cepeda, N. J., Pashler, H., Vul, E., Wixted, J. T., & Rohrer, D. (2006). Distributed practice in verbal recall tasks: A review and quantitative synthesis. Psychological Bulletin, 132(3), 354-380
Meta-analysis showing spaced repetition significantly improves long-term retention compared to massed practice
Carpenter, S. K., Cepeda, N. J., Rohrer, D., Kang, S. H., & Pashler, H. (2012). Using spacing to enhance diverse forms of learning: Review of recent research and implications for instruction. Educational Psychology Review, 24(3), 369-378
Review showing spacing effects work across different types of learning materials and contexts
Kang, S. H. (2016). Spaced repetition promotes efficient and effective learning: Policy implications for instruction. Policy Insights from the Behavioral and Brain Sciences, 3(1), 12-19
Policy review advocating for spaced repetition in educational settings based on extensive research evidence
Karpicke, J. D., & Roediger, H. L. (2008). The critical importance of retrieval for learning. Science, 319(5865), 966-968
Research demonstrating that active recall (retrieval practice) is more effective than re-reading for long-term learning
Roediger, H. L., & Butler, A. C. (2011). The critical role of retrieval practice in long-term retention. Trends in Cognitive Sciences, 15(1), 20-27
Review of research showing retrieval practice (active recall) as one of the most effective learning strategies
Dunlosky, J., Rawson, K. A., Marsh, E. J., Nathan, M. J., & Willingham, D. T. (2013). Improving students' learning with effective learning techniques: Promising directions from cognitive and educational psychology. Psychological Science in the Public Interest, 14(1), 4-58
Comprehensive review ranking learning techniques, with practice testing and distributed practice rated as highly effective

FlashRecall Team
FlashRecall Development Team
The FlashRecall Team is a group of working professionals and developers who are passionate about making effective study methods more accessible to students. We believe that evidence-based learning tec...
Credentials & Qualifications
- •Software Development
- •Product Development
- •User Experience Design
Areas of Expertise
Try FlashRecall on iPhone
Free tier after signup. AI flashcards from your notes, spaced repetition, and optional paid upgrade when you need more.
Download on App Store