
Q Learning: The Complete Beginner’s Guide To Smart Decision-Making
q learning in plain English: what the Q-table is, how the update rule works, and why it powers games, robots, and more—plus an easy way to remember it.
Want AI flashcards + spaced repetition on iPhone? FlashRecall is free to start (signup required; paid plans optional).
What Is Q Learning? (Explained Like You’re 5 Minutes From an Exam)
Alright, let’s talk about q learning: it’s a type of reinforcement learning where an agent learns which actions to take in each situation by trial and error, using rewards and punishments as feedback. Basically, q learning builds a table (called a Q-table) that says, “In this state, this action is this good.” Over time, it updates those values based on what happens next, so it slowly figures out the best way to act to get the highest total reward. This matters because it’s how we get computers to learn to play games, control robots, or make decisions without being explicitly told what to do. If you’re trying to actually remember how q learning works for class or a project, using flashcards in an app like Flashrecall can make all these formulas and concepts stick way easier:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Big Picture: How Q Learning Fits Into Reinforcement Learning
So, quick context before diving deeper:
- Reinforcement learning (RL) = an agent interacts with an environment and gets rewards.
- The goal: learn a policy (a strategy) that tells the agent what action to take in each state to maximize long-term reward.
- Q learning is one specific RL algorithm that learns a Q-value for each state–action pair.
Think of a Q-value like this:
> “If I’m in this situation and I do this action, how good is that choice in the long run?”
Instead of just caring about the immediate reward, q learning cares about the future too.
The Core Idea of Q Learning (Without the Scary Math First)
Here’s the idea in plain language:
1. The agent starts off kind of clueless.
2. It tries different actions in different states.
3. It sees what reward it gets and what state it ends up in.
4. It updates its belief about how good that action was.
5. Over time, after tons of trial and error, it learns which actions are best.
This is why q learning is used for:
- Game-playing (like teaching an AI to play gridworld or simple Atari games)
- Robot navigation
- Simple decision-making systems (e.g., choosing the best move or path)
The “Q” in Q learning usually stands for “quality” of an action in a state.
The Q Learning Formula (And What Each Piece Means)
Here’s the famous update rule you’ll see everywhere:
\[
Q(s, a) \leftarrow Q(s, a) + \alpha \big[ r + \gamma \max_{a'} Q(s', a') - Q(s, a) \big]
\]
Let’s decode this in normal language:
- Q(s, a): current estimate of how good action a is in state s
- α (alpha): learning rate (how fast you update your knowledge)
- r: reward you just got from taking action a in state s
- γ (gamma): discount factor (how much you care about future rewards vs immediate ones)
- s': the next state you land in
- maxₐ' Q(s', a'): the best possible Q-value from the next state (assuming you act optimally from there)
In words:
> New Q-value = Old Q-value + learning rate × (what you expected vs what actually happened)
Flashrecall automatically keeps track and reminds you of the cards you don't remember well so you remember faster. Like this :

It’s very similar to:
“I thought this was a 6/10 move, but I just learned it might actually be 8/10, so I’ll nudge my belief closer to 8.”
Why Q Learning Is a Big Deal
Q learning is popular because:
- It’s model-free – it doesn’t need to know the full rules of the environment.
- It can learn just from experience (states, actions, rewards).
- It can theoretically converge to the optimal policy if you explore enough and tune things right.
But the downside:
- For large or continuous state spaces, the Q-table becomes huge or impossible to store.
- That’s why we get Deep Q Learning (DQN), where a neural network approximates Q instead of a table.
If you’re learning this for class or research, it’s super easy to get lost in symbols. This is where having the key pieces broken into flashcards helps a ton.
Learning Q Learning Without Forgetting Everything Next Week
Q learning has a lot of moving parts:
- Definitions (state, action, reward, policy, value function, Q-function)
- The Q update formula
- Hyperparameters like α (learning rate) and γ (discount factor)
- Concepts like exploration vs exploitation (ε-greedy policy)
- Variants like Deep Q Networks (DQN)
Trying to just reread your notes doesn’t really cut it. You need active recall and spaced repetition to lock it in.
That’s exactly the kind of thing an app like Flashrecall is perfect for:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
You can:
- Turn your lecture slides, PDF notes, or screenshots of the Q learning equations into instant flashcards.
- Use built-in spaced repetition so the key formulas and concepts come back just before you forget them.
- Practice active recall by seeing the term “Q learning update rule” and forcing yourself to write or say the formula before flipping.
How To Turn Q Learning Into Flashcards (Concrete Examples)
Here’s how I’d break q learning into cards in Flashrecall.
1. Core Definitions
- Front: What is q learning in reinforcement learning?
- Front: What does Q(s, a) represent?
- Front: What are the main components of a reinforcement learning setup?
2. Formula Breakdown
- Front: Write the Q learning update formula.
- Front: In q learning, what does α (alpha) control?
- Front: In q learning, what does γ (gamma) control?
With Flashrecall, you can literally just type these in or:
- Snap a photo of your textbook page with the Q formula.
- Let the app auto-generate flashcards from that image.
- Clean them up quickly and start reviewing.
Exploration vs Exploitation (The ε-Greedy Trick)
One huge part of q learning is how the agent chooses actions:
- Exploitation: Pick the action with the highest current Q-value (best guess so far).
- Exploration: Try random actions to discover potentially better options.
The common strategy is ε-greedy:
- With probability ε: choose a random action (explore).
- With probability 1 - ε: choose the best-known action (exploit).
You can make flashcards like:
- Front: What is ε-greedy in q learning?
- Front: Why is exploration important in q learning?
Flashrecall’s active recall makes you repeatedly pull these definitions from memory instead of just rereading them, which is exactly what you need for exam-style questions.
Where Q Learning Is Used (So It Feels Less Abstract)
Some real and common uses:
- Gridworld problems in textbooks
- Game AI: simple games, maze-solving, or toy problems
- Robot navigation: learning paths without a full map
- Resource allocation / scheduling in simplified settings
You can make scenario-based cards too:
- Front: Give an example of a problem where q learning is suitable.
Studying Q Learning With Flashrecall (Step-by-Step)
Here’s a simple way to use Flashrecall to actually remember q learning long term:
1. Dump your material in
- Import PDF slides, take photos of your notes, or paste text.
- Flashrecall can auto-generate flashcards from this content so you’re not typing everything.
2. Clean and organize
- Group cards into a “Reinforcement Learning” or “Q Learning” deck.
- Add tags like `definitions`, `formulas`, `examples`, `intuition`.
3. Use spaced repetition
- Flashrecall has built-in spaced repetition with auto reminders, so you don’t have to manually plan review days.
- This is perfect for math-heavy topics where you forget fast if you don’t revisit them.
4. Practice active recall daily
- Don’t just read the back. Try to say the formula, draw the Q-table, or explain ε-greedy out loud before flipping.
5. Ask questions when stuck
- Flashrecall lets you chat with your flashcards if you’re unsure about something.
- So if you forget what gamma really does, you can literally ask and get a clearer explanation right there.
You can grab Flashrecall here (it’s free to start and works on iPhone and iPad):
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Why Flashrecall Works Really Well For Stuff Like Q Learning
Q learning isn’t just “memorize one definition and you’re done.” You’ve got:
- Symbols and formulas
- Intuition and explanations
- Code-level understanding (if you’re implementing it)
- Differences vs other RL methods
Flashrecall helps with this kind of layered understanding because:
- It’s fast and modern – you can create cards from images, text, PDFs, YouTube links, or manual input.
- It has offline support, so you can review your RL cards on the train or in boring lectures.
- You get study reminders so you don’t forget to review the topic two days before the exam.
- It’s great not just for q learning, but also for other ML topics, math, exams, languages, medicine, business, anything.
You basically turn your complicated course into small, bite-sized questions your brain can actually handle.
Quick Recap: What You Should Remember About Q Learning
If you remember nothing else, remember this:
- Q learning is a reinforcement learning algorithm that learns how good actions are in each state using a Q-value.
- It updates Q-values using the formula with α, γ, and the max Q of the next state.
- It uses trial and error plus exploration vs exploitation to find a good policy.
- It’s the foundation for more advanced stuff like Deep Q Networks (DQN).
And if you want all of that to stay in your head longer than a week, turn it into flashcards and let spaced repetition do the heavy lifting. Flashrecall makes that part stupidly easy:
https://apps.apple.com/us/app/flashrecall-study-flashcards/id6746757085
Use it to break q learning into small questions, review a bit each day, and you’ll walk into your exam or project meeting actually remembering how it works.
Frequently Asked Questions
What's the fastest way to create flashcards?
Manually typing cards works but takes time. Many students now use AI generators that turn notes into flashcards instantly. Flashrecall does this automatically from text, images, or PDFs.
Is there a free flashcard app?
Yes. Flashrecall is free and lets you create flashcards from images, text, prompts, audio, PDFs, and YouTube videos.
How can I study more effectively for this test?
Effective exam prep combines active recall, spaced repetition, and regular practice. Flashrecall helps by automatically generating flashcards from your study materials and using spaced repetition to ensure you remember everything when exam day arrives.
Related Articles
FlashRecall app preview
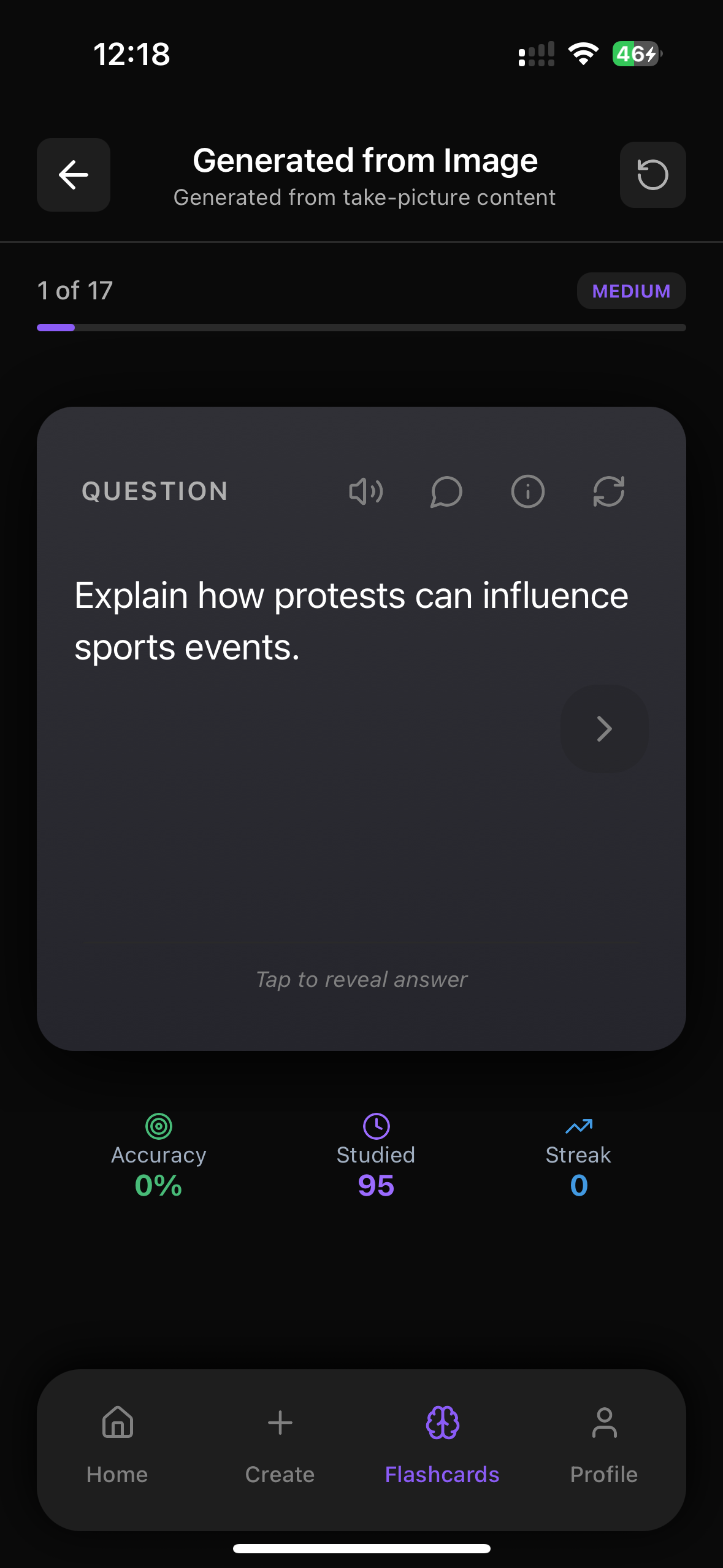
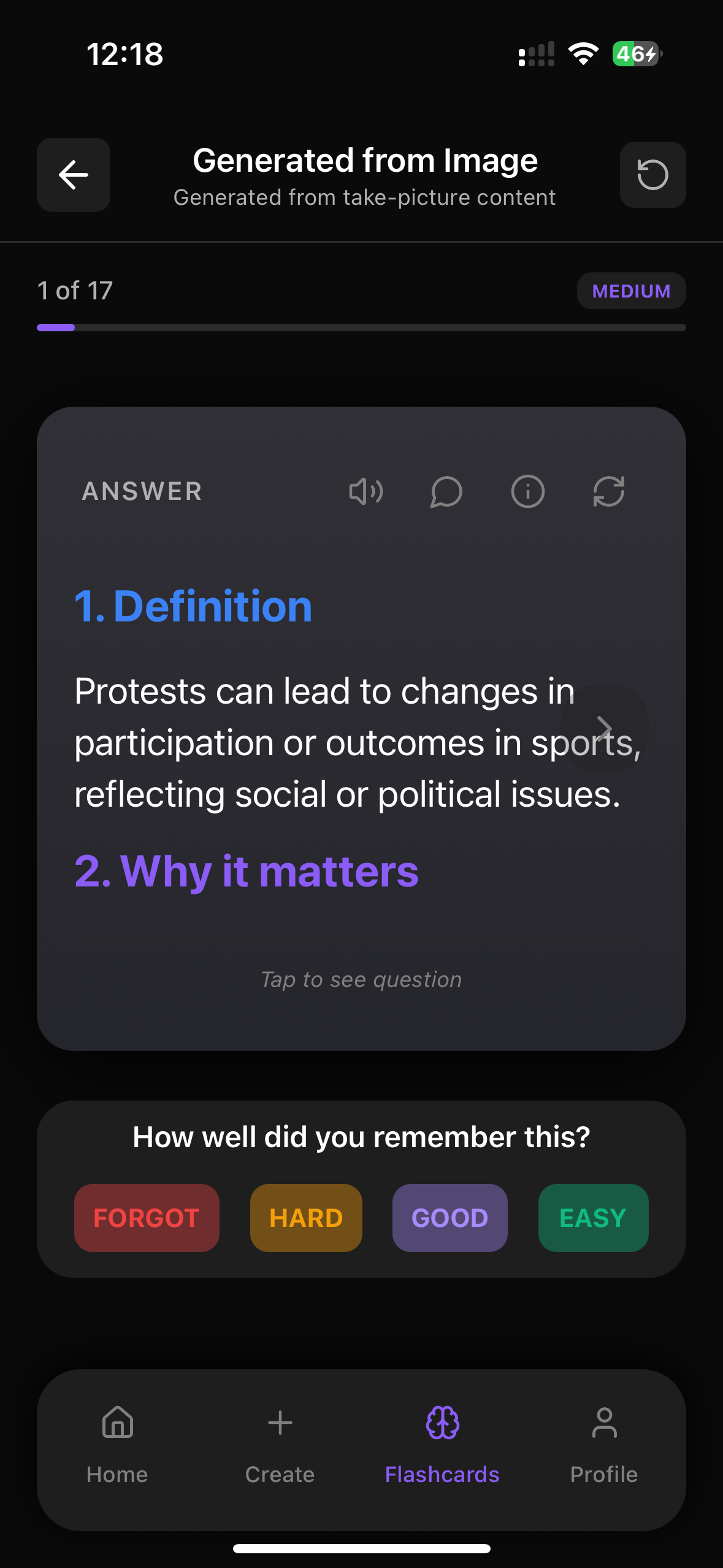
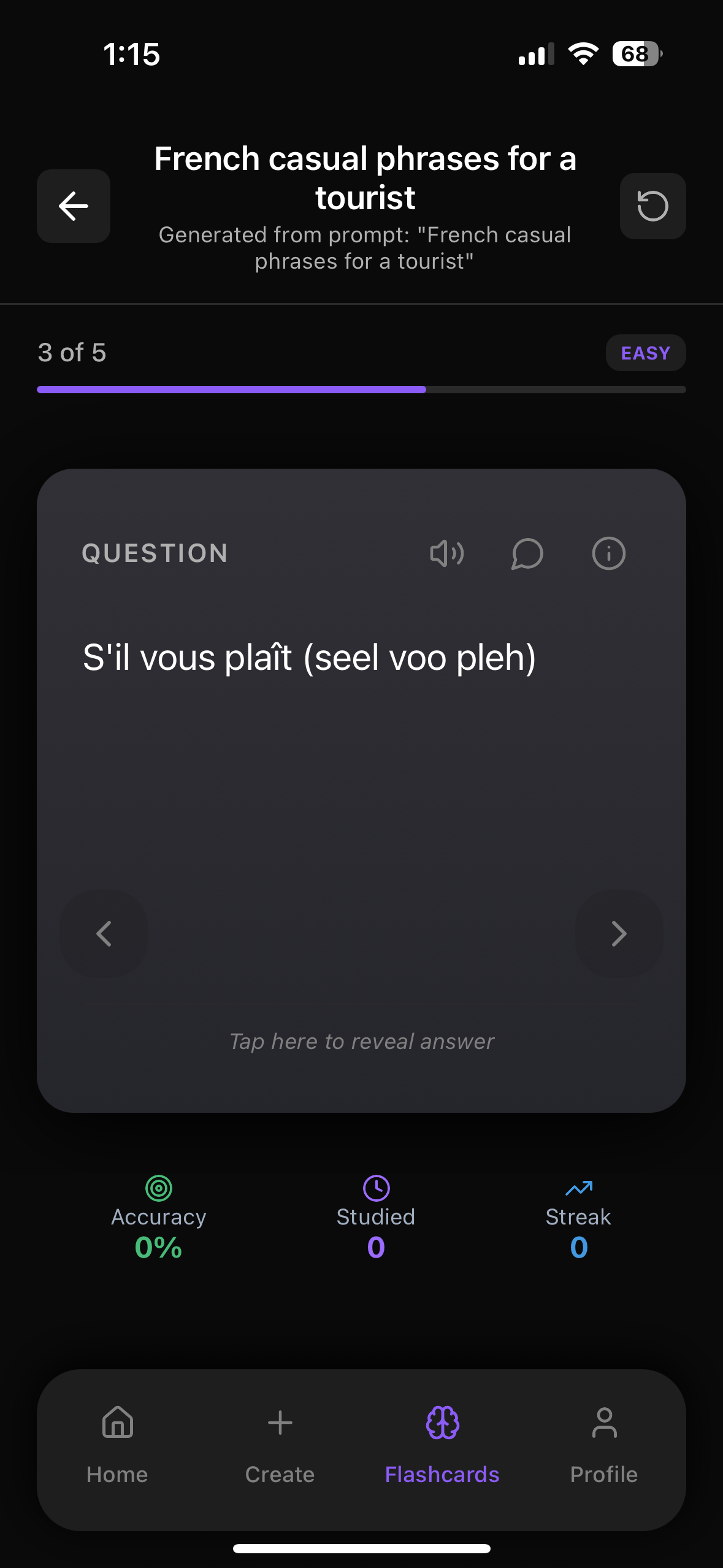
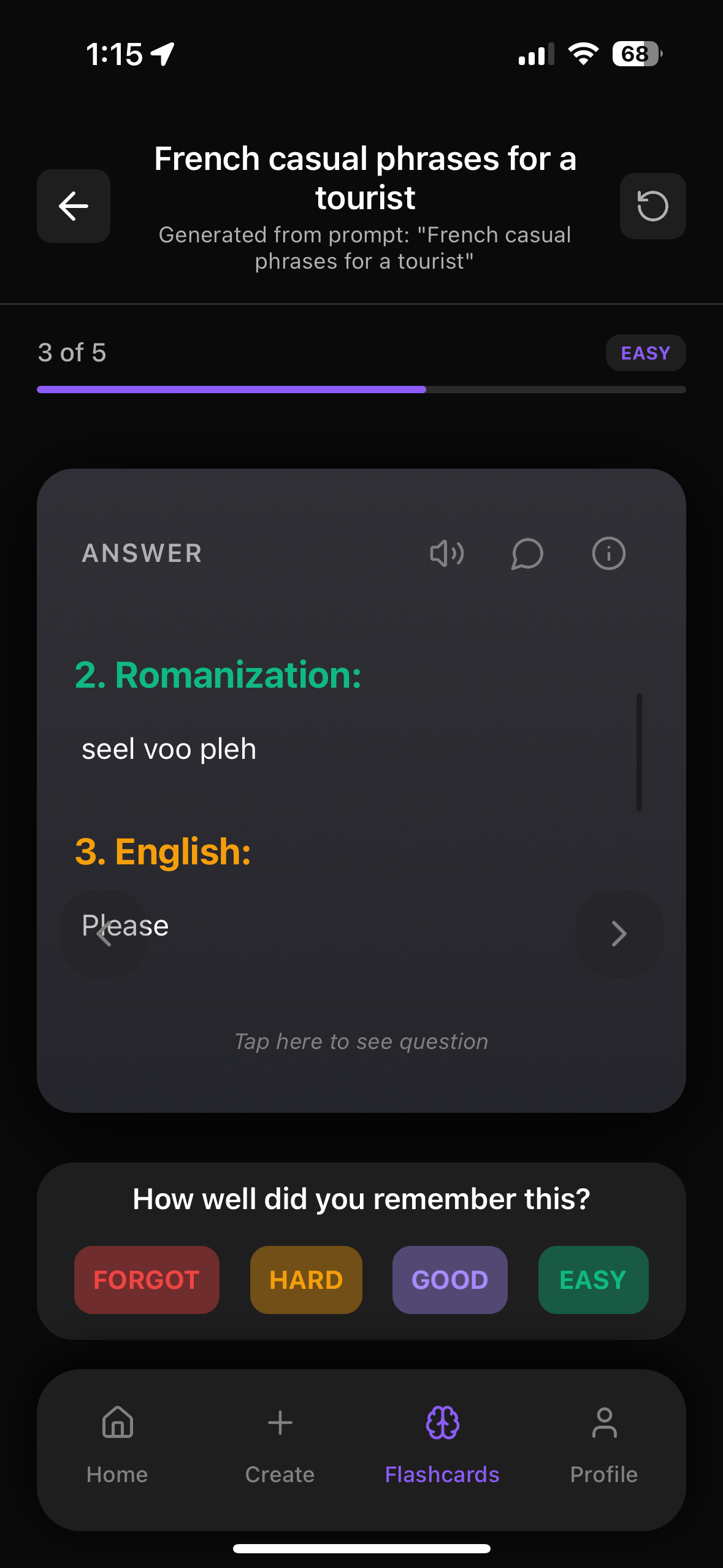
Practice This With Web Flashcards
Try our web flashcards right now to test yourself on what you just read. You can click to flip cards, move between questions, and see how much you really remember.
Try Flashcards in Your BrowserInside the FlashRecall app you can also create your own decks from images, PDFs, YouTube, audio, and text, then use spaced repetition to save your progress and study like top students.
Research References
The information in this article is based on peer-reviewed research and established studies in cognitive psychology and learning science.
Cepeda, N. J., Pashler, H., Vul, E., Wixted, J. T., & Rohrer, D. (2006). Distributed practice in verbal recall tasks: A review and quantitative synthesis. Psychological Bulletin, 132(3), 354-380
Meta-analysis showing spaced repetition significantly improves long-term retention compared to massed practice
Carpenter, S. K., Cepeda, N. J., Rohrer, D., Kang, S. H., & Pashler, H. (2012). Using spacing to enhance diverse forms of learning: Review of recent research and implications for instruction. Educational Psychology Review, 24(3), 369-378
Review showing spacing effects work across different types of learning materials and contexts
Kang, S. H. (2016). Spaced repetition promotes efficient and effective learning: Policy implications for instruction. Policy Insights from the Behavioral and Brain Sciences, 3(1), 12-19
Policy review advocating for spaced repetition in educational settings based on extensive research evidence
Karpicke, J. D., & Roediger, H. L. (2008). The critical importance of retrieval for learning. Science, 319(5865), 966-968
Research demonstrating that active recall (retrieval practice) is more effective than re-reading for long-term learning
Roediger, H. L., & Butler, A. C. (2011). The critical role of retrieval practice in long-term retention. Trends in Cognitive Sciences, 15(1), 20-27
Review of research showing retrieval practice (active recall) as one of the most effective learning strategies
Dunlosky, J., Rawson, K. A., Marsh, E. J., Nathan, M. J., & Willingham, D. T. (2013). Improving students' learning with effective learning techniques: Promising directions from cognitive and educational psychology. Psychological Science in the Public Interest, 14(1), 4-58
Comprehensive review ranking learning techniques, with practice testing and distributed practice rated as highly effective

FlashRecall Team
FlashRecall Development Team
The FlashRecall Team is a group of working professionals and developers who are passionate about making effective study methods more accessible to students. We believe that evidence-based learning tec...
Credentials & Qualifications
- •Software Development
- •Product Development
- •User Experience Design
Areas of Expertise
Try FlashRecall on iPhone
Free tier after signup. AI flashcards from your notes, spaced repetition, and optional paid upgrade when you need more.
Download on App Store